info
The foundation is not firm, and the ground is shaking.Regardless of the architecture, the choice of underlying storage is a topic worth exploring.Storage carries the data of the business, and its performance directly affects the actual performance of the business application.It is precisely because the data of storage and business are closely related, and its reliability must also be paid attention to. Once the failure of storage leads to the loss of business data, it will be a disaster-level accident.
1. The path of storage choices in the cloud-native era
In recent years, my work has always revolved around the construction of customer Kubernetes clusters.How to choose a stable and reliable storage solution with excellent performance for the customer's Kubernetes cluster has always troubled me.
The most basic functional requirement that the storage volume can be remounted after the Pod is drifted to another node made me focus on the storage type of the shared file system from the beginning.I chose Nfs at the beginning, and then put it into the embrace of Glusterfs. Until recently, I started to explore other better cloud-native storage solutions. Along the way, I also have a certain understanding of various storages.They each have their own characteristics:
Nfs:Nfs is an old-fashioned storage solution based on network sharing files.Its advantage is simplicity and efficiency.Its shortcomings are also more obvious, the server has a single point of failure, and there is no replication mechanism for data.In some scenarios that do not require high reliability, Nfs is still the best choice.
Glusterfs:is an open source distributed shared storage solution.Compared with Nfs, Gfs improves the reliability of data through multi-copy replica sets, and the mechanism of adding Brick also makes the expansion of the storage cluster no longer limited to one server.Gfs was once the first choice of our department in the production environment. By setting the replication factor to 3, the reliability of the data can be ensured, and the problem of data split-brain in the distributed system can be avoided.After going forward with Gfs for a long time, we also found its performance shortcomings in the scenario of intensive small file reading and writing.Moreover, the storage of a single shared file system type gradually no longer meets the needs of our usage scenarios.
Our search for more suitable storage has not stopped.In the past two years, the concept of cloud native has become very popular, and various cloud native projects have emerged in the community, including storage-related projects.At first, we focused on Ceph, which attracted us most because of its high-performance block device type storage.However, it was once persuaded by its complex deployment method and high operation and maintenance threshold.The emergence of Rook, the CNCF graduation project, finally leveled the last threshold for contacting Ceph.
The Rook project provides a cloud-native storage orchestration tool, provides platform-level and framework-level support for various types of storage, and manages the installation, operation and maintenance of storage software.Rook officially included Ceph Operator as a stable supported feature in version 0.9 released in 2018, and it has been several years so far.Using Rook to deploy and manage a production-level Ceph cluster is quite robust.
Compared with Gfs, Rook-Ceph provides block device type storage with extremely high performance, which is equivalent to mounting a hard disk for Pod, and it is not difficult to deal with the scenario of intensive small file reading and writing.In addition to providing block device type storage, Rook-Ceph can also provide distributed shared storage based on Cephfs, and object storage based on the S3 protocol.Unified management of multiple storage types, and a visual management interface is provided, which is very friendly to operation and maintenance personnel.
As a CNCF graduate project, Rook-Ceph's support for cloud-native scenarios is beyond doubt.The deployed Rook-Ceph cluster provides a CSI plug-in, which provides data volumes to Kubernetes in the form of StorageClass, and is also very friendly to various cloud-native PaaS platforms that are compatible with the CSI specification.
2. The connection between Rainbond and Rook
In Rainbond V5.7.0-release, support for the Kubernetes CSI container storage interface was added.
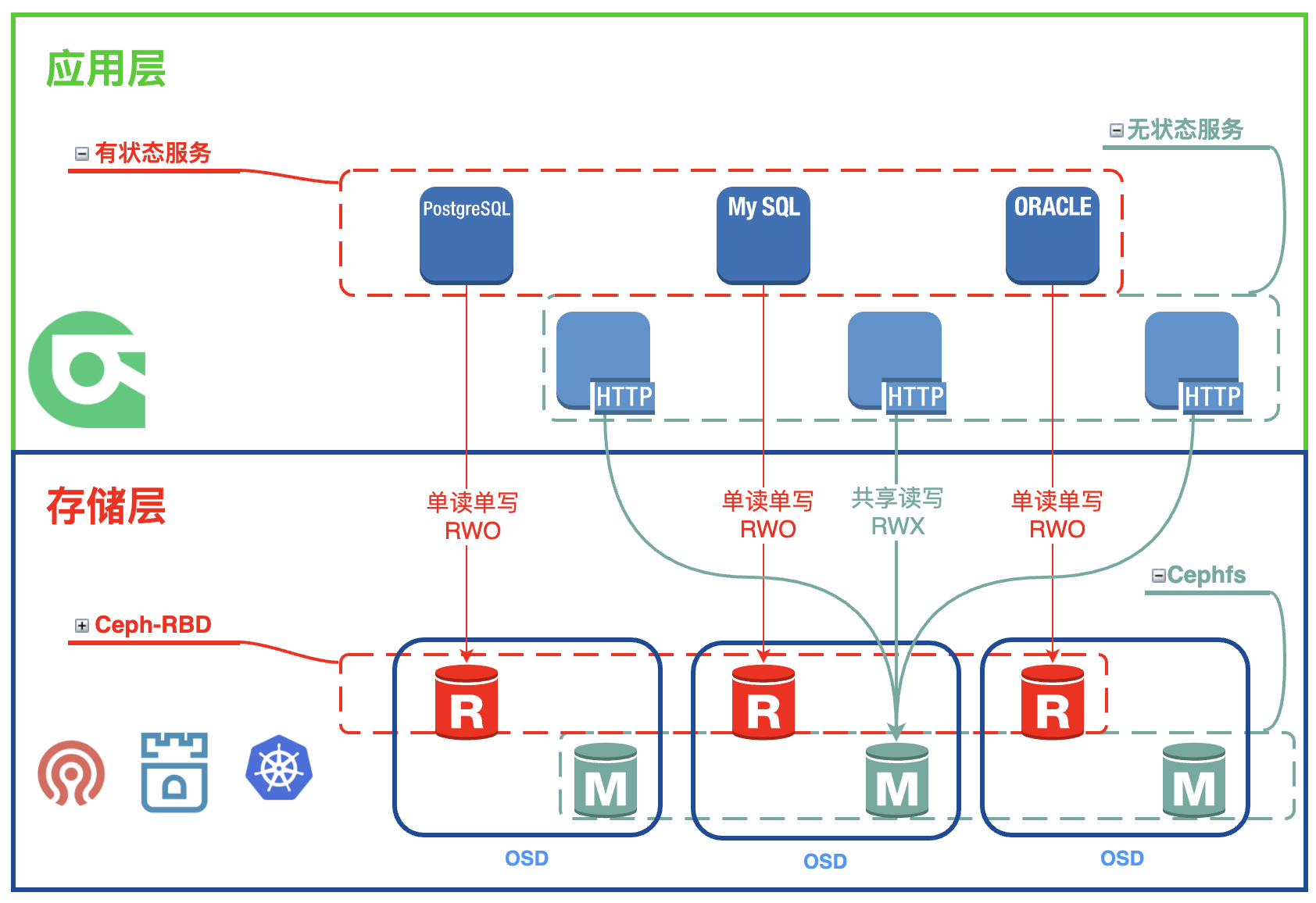
During the installation and deployment phase of Rainbond, Cephfs will be referenced to deploy the shared storage provided by default for all service components.For stateful service components, when adding persistent storage, you can select all available StorageClasses in the current cluster, and you can apply for a block device to mount by selecting rook-ceph-block , and the whole process is graphically interfaced. Very convenient.
How to deploy Rook-Ceph and connect it to Rainbond, please refer to document Rook-Ceph connection solution.
3. User experience
In this chapter, I will describe the various usage experiences after Rainbond is connected to Rook-Ceph storage in an intuitive way.
3.1 Using shared storage
Rainbond connects to Cephfs as a cluster shared storage by specifying parameters during the installation phase.In the process of using Helm to install Rainbond, the key docking parameters are as follows:
--set Cluster.RWX.enable=true \
--set Cluster.RWX.config.storageClassName=rook-cephfs \
--set Cluster.RWO.enable=true \
--set Cluster.RWO.storageClassName=rook -ceph-block
For any service component deployed on the Rainbond platform, it is only necessary to select the default shared storage when mounting the persistent storage, which is equivalent to persistently saving the data into the Cephfs file system.
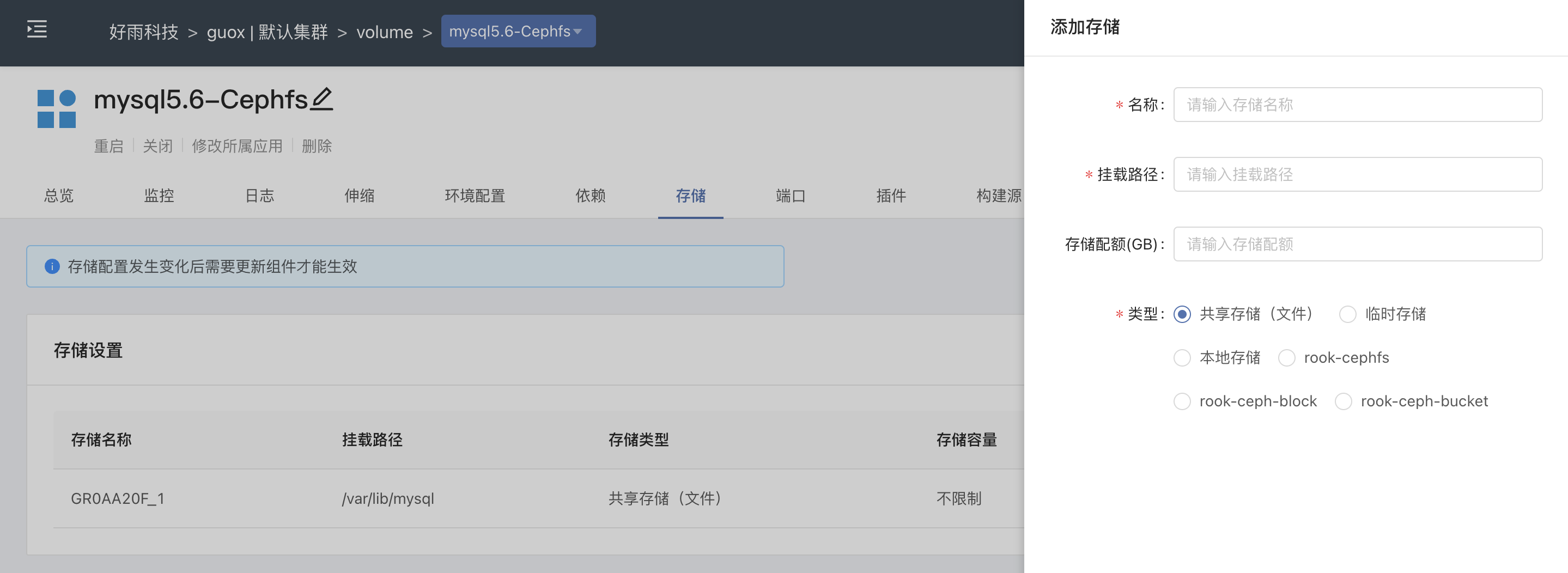
Using the English name of the component in the cluster can filter the PV resources generated by the query:
$ kubectl get pv | grep mysqlcephfs
pvc-faa3e796-44cd-4aa0-b9c9-62fa0fbc8417 500Gi RWX Retain Bound guox-system/manual7-volume-mysqlcephfs-0 rainbondsssc 2m7s
3.2 Mounting a block device
Except for the default shared storage, all StorageClasses in the cluster are exposed to stateful services.Manually select rook-ceph-block to create block device type storage and mount it for Pod use.When the service component has multiple instances, each Pod will generate a block device mount to use.
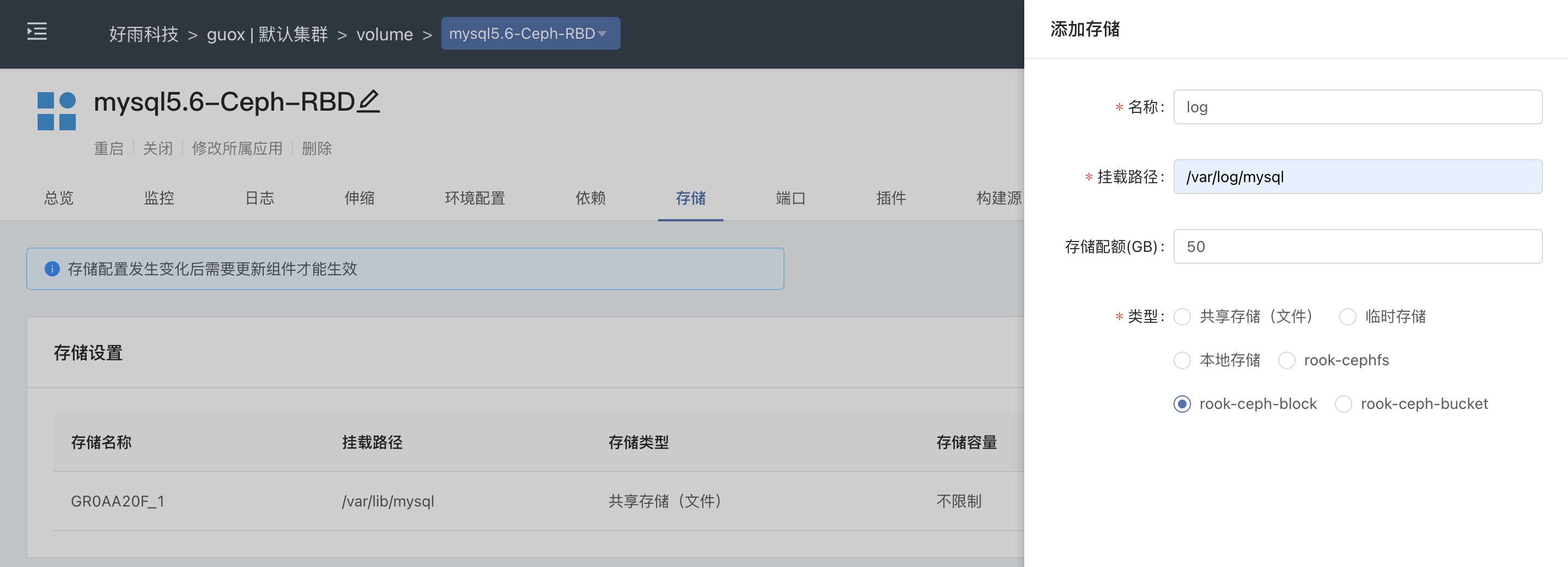
Query the generated PV resource:
$ kubectl get pv | grep mysql6-0
pvc-5172cb7a-cf5b-4770-afff-153c981ab09b 50Gi RWO Delete Bound guox-system/manual6-app-a710316d-mysql6-0 rook-ceph-block 5h15m
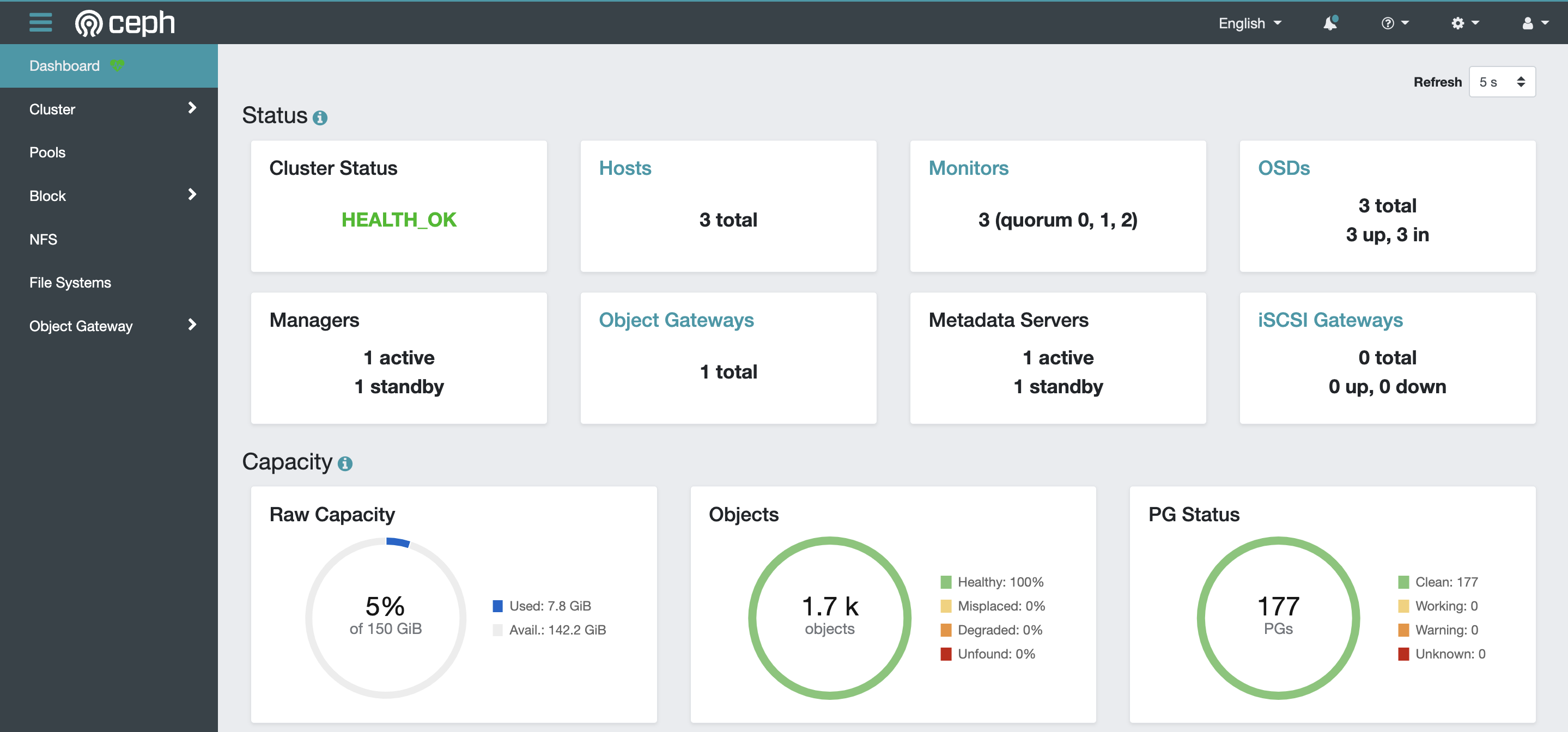
3.3 Open the dashboard
The visual operation interface Ceph-dashboard is installed by default when Rook-Ceph is deployed.Here, you can monitor the entire storage cluster, and you can also change the configuration of various storage types based on graphical interface operations.
Modify Ceph cluster configuration to disable dashboard built-in ssl:
$ kubectl -n rook-ceph edit cephcluster -n rook-ceph rook-ceph
# Modify ssl to false
spec:
dashboard:
enabled: true
ssl: false
# Restart the operator to make the configuration take effect
$ kubectl delete po - l app=rook-ceph-operator -n rook-ceph
$ kubectl -n rook-ceph get service rook-ceph-mgr-dashboard
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-mgr-dashboard ClusterIP 10.43.210.36 <none> 7000/TCP 118m
Obtain svc, use third-party components as an agent on the platform, and open the external service address to access the dashboard through the gateway.
After accessing the dashboard, the default user isadmin, execute the following command on the server to obtain the password:
kubectl -n rook-ceph get secret rook-ceph-dashboard-password -o jsonpath="{['data']['password']}" | base64 --decode && echo
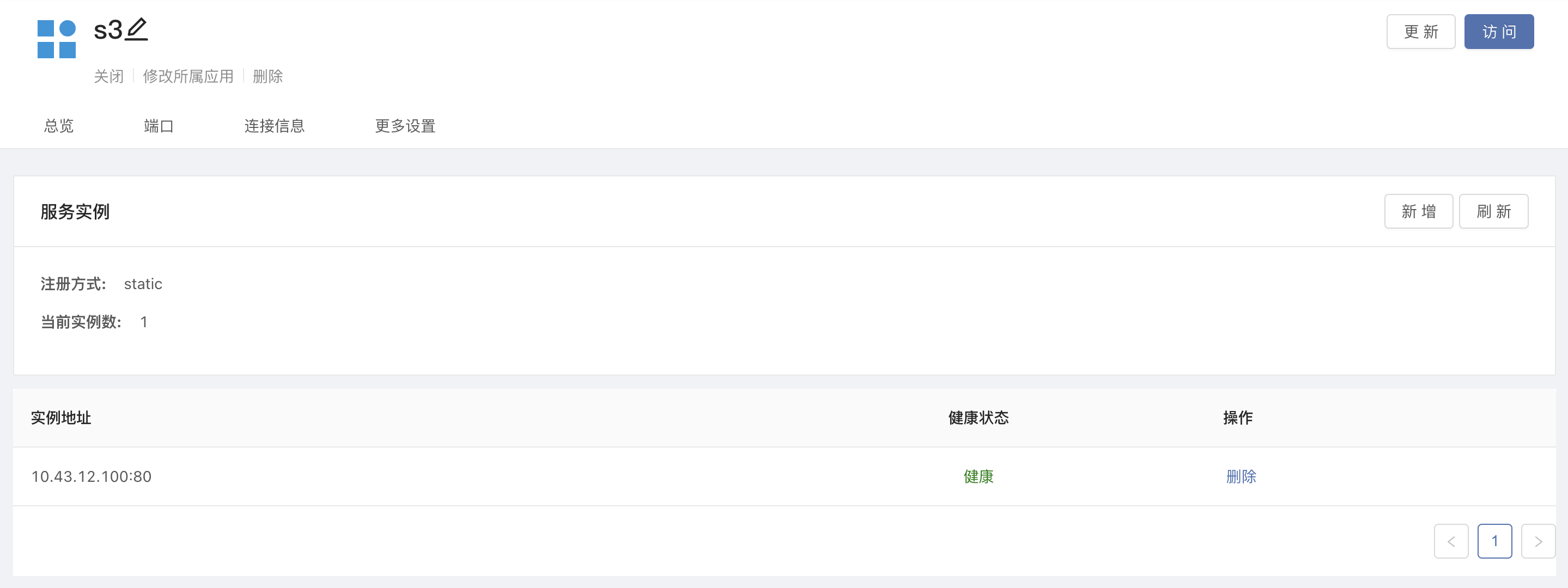
3.4 Using Object Storage
Please refer to document Rook-Ceph deployment interface , you can deploy object storage in Rook-Ceph.By simply passing the service ClusterIP of the object storage through a third-party service proxy, we can obtain an object storage address that can be accessed by multiple clusters managed by the same console at the same time.Rainbond can implement cloud backup and migration based on this feature.
Get the svc address:of the object store
$ kubectl -n rook-ceph get service rook-ceph-rgw-my-store
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
rook-ceph-rgw-my-store ClusterIP 10.43.12.100 <none> 80/TCP 3h40m
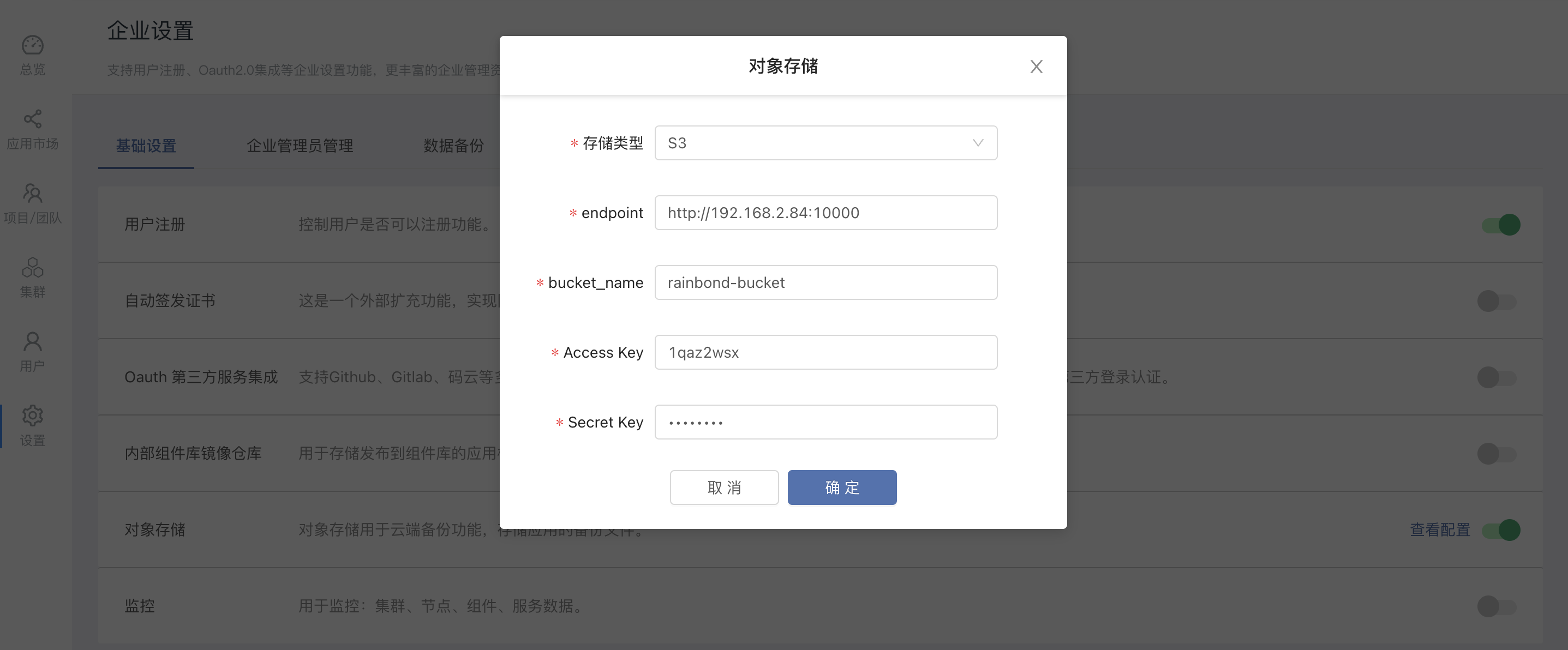
By filling in the object storage bucket, access-key, and secret-key created in Ceph-dashboard in advance in the enterprise settings, you can connect to the object storage.
4. Performance comparison test
We use the sysbench tool to test the performance of Mysql using different types of storage. Except that the data directory is mounted with different types of storage, other experimental conditions are the same.The storage types participating in the test include Glusterfs, Cephfs, and Ceph-RBD.
The data collected are transactions per second (TPS) and requests per second (QPS) returned by the sysbench test:
| storage type | Mysql memory | QPS | TPS |
|---|---|---|---|
| Glusterfs | 1G | 4600.22 | 230.01 |
| Cephfs | 1G | 18095.08 | 904.74 |
| Ceph-RBD | 1G | 24852.58 | 1242.62 |
The test results are obvious, the Ceph block device has the highest performance, and Cephfs also has obvious performance advantages over Glusterfs.
5. Write at the end
Adapting to the Kubernetes CSI container storage interface is a major feature of Rainbond v5.7.0-release. This feature allows us to easily interface with Rook-Ceph, an excellent storage solution.Through the description of the use experience of Rook-Ceph and the final performance test comparison, it has to be said that Rook-Ceph will soon become a main direction of our exploration in the field of cloud native storage.