GPU 管理
概述
Rainbond GPU 高级管理插件为平台�提供企业级的 GPU 算力调度能力。在默认的 Kubernetes 环境中,GPU 只能以整卡为单位进行独占式分配,导致显存利用率低、资源浪费严重。本插件通过 GPU 虚拟化与池化技术,支持将物理 GPU 切分为细粒度的 vGPU,实现多任务共享与硬隔离,同时统一纳管不同品牌和型号的异构 GPU。
功能对比
下表对比了基础开源方案与本插件在 GPU 管理方面的差异:
| 维度 | 基础开源方案 | GPU 高级管理插件 |
|---|---|---|
| 资源分配 | 只能分配整数张卡(1 张、2 张等) | 支持细粒度切分(如 0.2 张卡,或指定 4GB 显存),单卡可供多个服务同时使用 |
| 异构纳管 | 需针对每种显卡手动编写调度策略 | 统一纳管 Nvidia、AMD 及国产信创 GPU(昇腾、海光等),屏蔽底层硬件差异 |
| 安全隔离 | 共享时容易发生显存 OOM 互相影响 | 提供显存与算力的硬隔离,多租户共享时互不干扰 |
| 运维成本 | 需投入专人持续维护底层调度组件 | 通过平台界面启用和配置,降低运维复杂度 |
示例场景
假设集群中有 4 张 A100 (80GB) 显卡。在整卡分配模式下,最多分配给 4 个推理服务。启用本插件后,可按需切分为 16 个 20GB 显存的 vGPU,支撑 16 个服务并发运行。实际切分粒度取决于业务的显存和算力需求。
核心能力
异构 GPU 资源池化
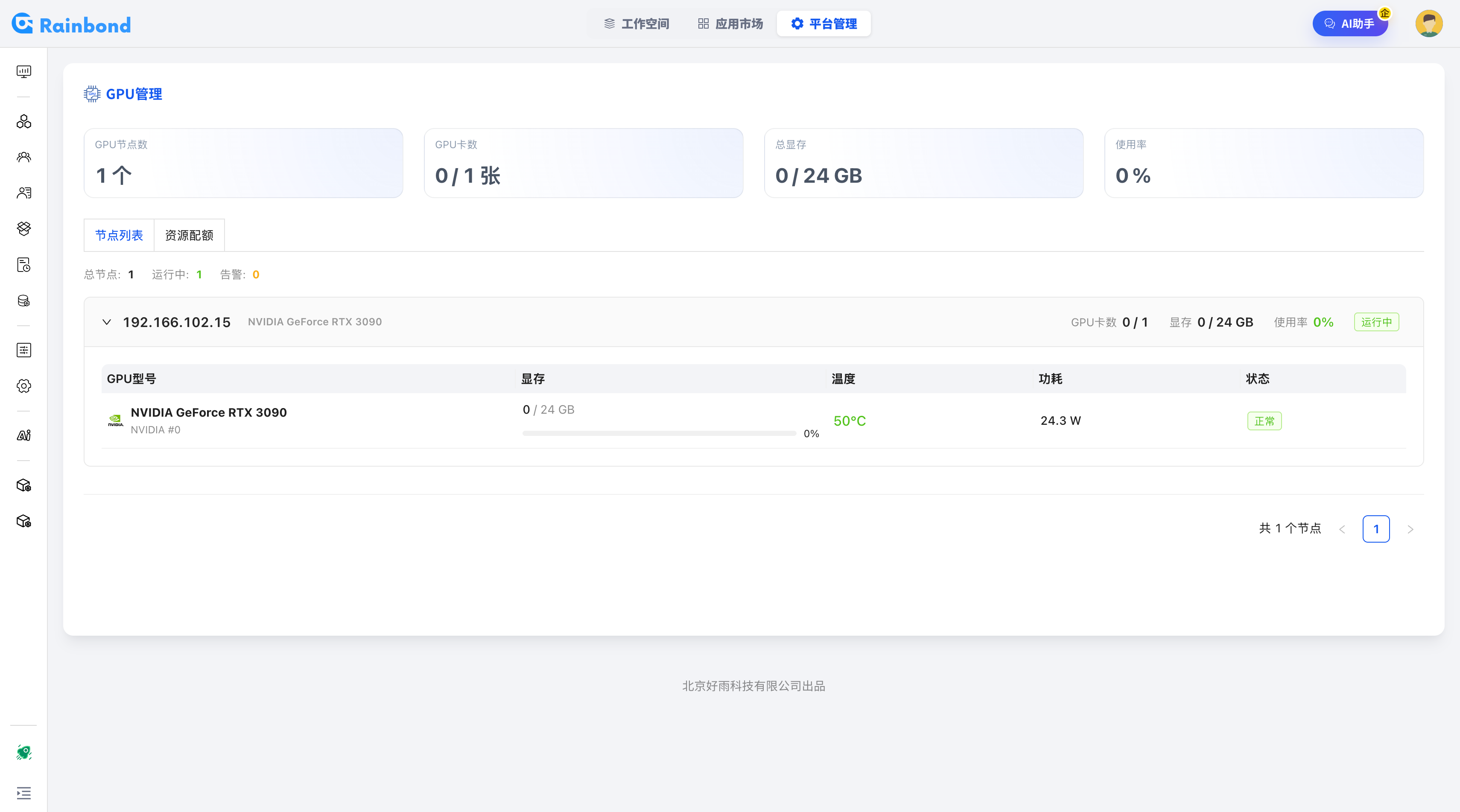
插件自动识别集群内的所有 GPU 节点,将不同品牌和型号的 GPU 汇聚为统一的算力资源池。在资源总览页面可以直观查看 GPU 节点数、卡数、总显存及整体使用率,并下钻至每个节点查看 GPU 型号、显存、温度、功耗等详细信息。
- 支持主流 Nvidia 系列(A100、V100、T4、RTX 系列等)
- 支持国产信创 GPU(昇腾、海光等)
细粒度 vGPU 共享与隔离
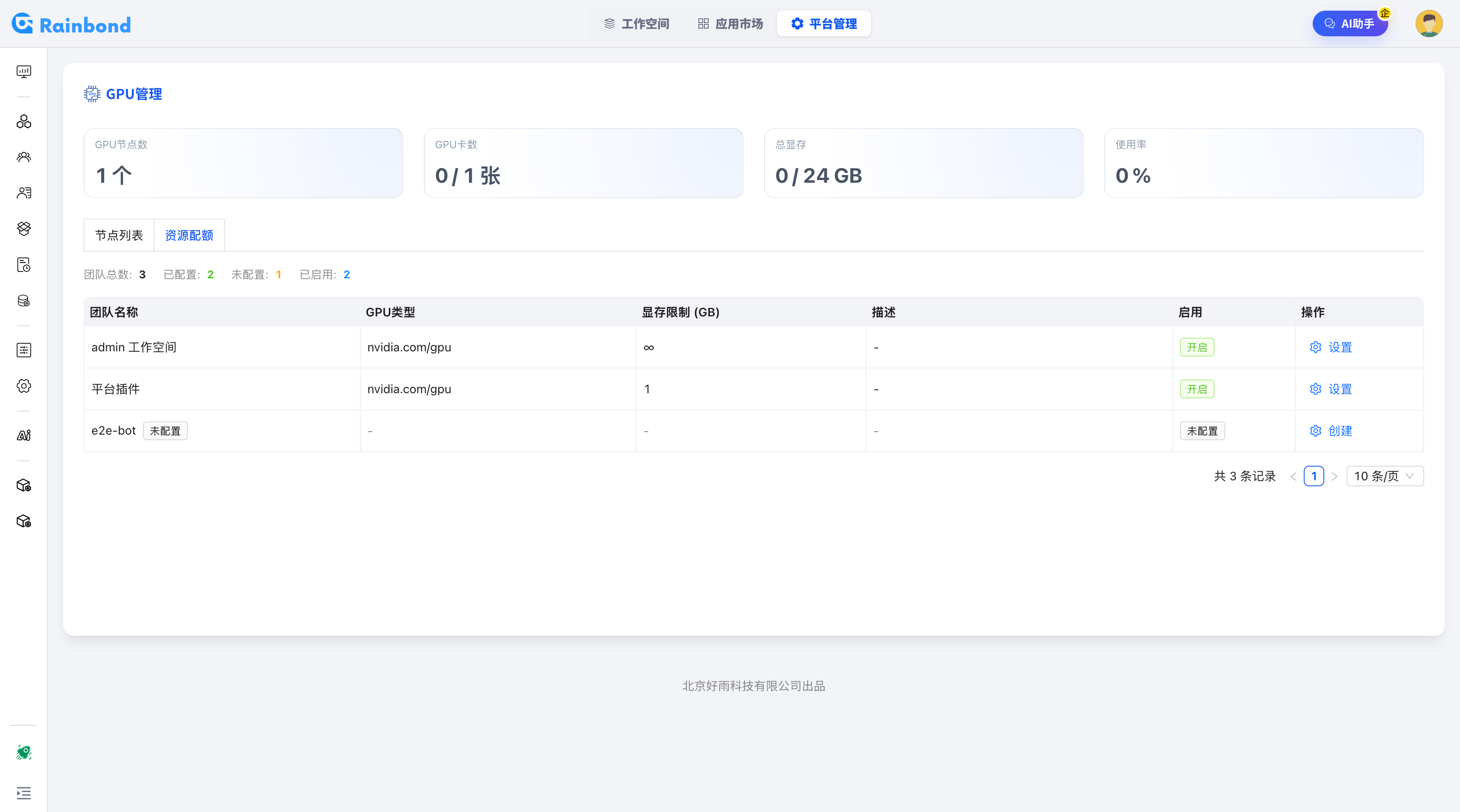
平台管理员可按团队维度配置 GPU 显存配额,限制每个团队可使用的最大显存量,实现多租户间的资源隔离。
- 团队级配额:为每个团队设定 GPU 显存上限(如 admin 工作空间 10 GB、平台插件 5 GB),防止资源被单一团队耗尽
- 显存隔离:严格限制每个组件可使用的最大显存,防止越权占用
GPU 可观测性
在资源池总览页面内置实时监控,展示每张物理 GPU 的运行状态。
- 监控每张物理卡的显存用量、温度、功耗和运行状态
- 支持按节点下钻查看 GPU 详情,辅助进行算力容量规划
使用指南
启用插件
- 进入 平台管理 -> 插件中心,找到「GPU 高级管理」插件并启用。
为组件配置 GPU 资源
- 进入需要使用 GPU 的组件,切换到 GPU 管理 标签页。
- 将「启用 GPU」设为 启用,选择 GPU 类型(如 NVIDIA)。
- 填写所需的 GPU 卡数(如
1张)。 - 选择 共享模式 或 独占模式:
- 共享模式:多个组件共享同一张 GPU,按显存配额隔离
- 独占模式:组件独占整张 GPU
- 在共享模式下,输入所需的 GPU 显存数(如
10.0GB)。 - 点击 保存配置 使设置生效。
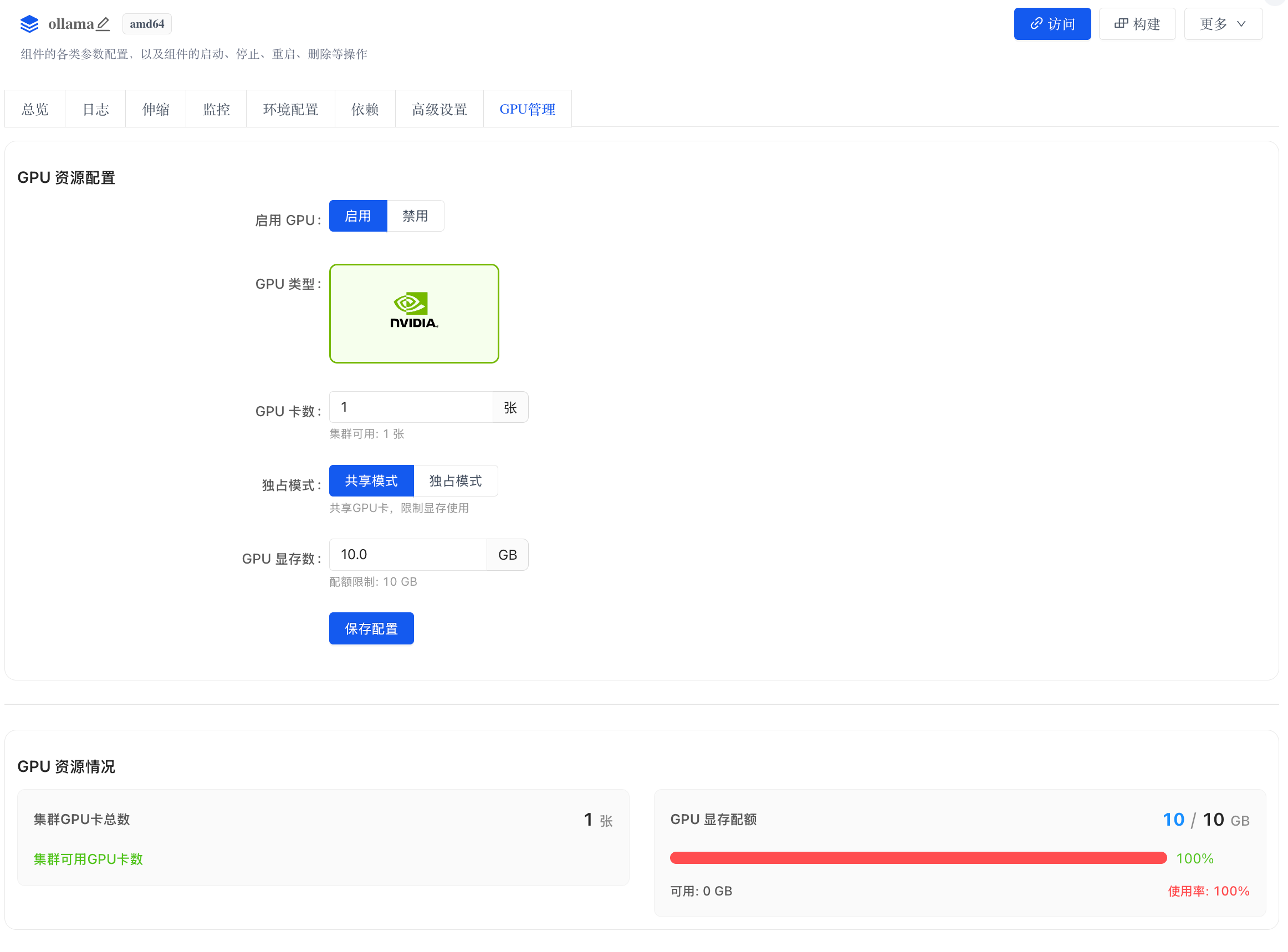
配置完成后,页面底部的「GPU 资源情况」会实时展示集群 GPU 卡总数和显存配额使用率。