K8S 部署 Deepseek 要 3 天?别逗了!Ollama+GPU Operator 1 小时搞定
最近一年我都在依赖大模型辅助工作,比如 DeepSeek、豆包、Qwen等等。线上大模型确实方便,敲几个字就能生成文案、写代码、做表格,极大提高了效率。但对于企业来说:公司内部数据敏感、使用外部大模型会有数据泄露的风险。
尤其是最近给 Rainbond 开源社区的用户答疑时,发现大家对大模型私有化部署有需求,都希望把大模型部署到企业内网,既能按需定制优化,又能保障安全合规。
网上教程虽多,但大多零散且偏向极客操作,真正能落地到生产环境的少之又少。稍微花了点时间,终于跑通了一套全链路解决方案:
- Ollama:让大模型从文件变成可运行的服务,专治模型跑不起来的千古难题。
- RKE2:RKE2 是 Rancher 推出的轻量化 K8s,比传统 K8s 节省 50% 资源,适合本地服务器。
- Rainbond:让复杂的集群管理去技术化,非运维人员也能轻松管好大模型服务。
- GPU Operator:一站式部署,显卡驱动安装零干预、容器运行时统一管理、深度集成 K8S。
这套组合对开发者和企业来说,意味着效率与安全的双重升级:开发者无需处理模型环境和集群配置,Ollama+Rainbond 让部署从 “写代码” 变成 “点鼠标”,专注业务逻辑;企业则实现数据本地化,通过 RKE2 安全策略和 Rainbond 权限管理满足合规要求,搭配 GPU Operator 提升硬件利用率,让私有化部署既简单又高效。
接下来的教程,我会从服务器准备到环境搭建再到大模型部署,拆解每个关键步骤。无论你是想搭建企业专属大模型服务,还是探索本地化 AI 应用,跟着教程走,都能少走弯路,快速落地一个安全、高效、易管理的大模型部署方案。
准备
首先需要一台干净的 GPU 服务器,推荐硬件配置如下(以 NVIDIA A100 为例):
- CPU:14 核及以上
- 内存:56GB 及以上
- GPU:NVIDIA A100(24GB 显存,支持其他 CUDA 兼容显卡,需确认GPU Operator 支持列表
- 操作系统:Ubuntu 22.04(需匹配 GPU Operator 支持的系统版本
部署 RKE2
先以单节点集群为例快速落地演示。
1. 创建 RKE2 配置
创建私有镜像仓库配置(Rainbond 默认的私有镜像仓库)
mkdir -p /etc/rancher/rke2
cat > /etc/rancher/rke2/registries.yaml << EOF
mirrors:
"goodrain.me":
endpoint:
- "https://goodrain.me"
configs:
"goodrain.me":
auth:
username: admin
password: admin1234
tls:
insecure_skip_verify: true
EOF
创建集群基础配置
cat > /etc/rancher/rke2/config.yaml << EOF
disable:
- rke2-ingress-nginx #禁用默认Ingress,会与Rainbond网关冲突
system-default-registry: registry.cn-hangzhou.aliyuncs.com # 国内镜像仓库
EOF
2. 安装并启动 RKE2
通过国内镜像加速安装,提升部署速度
# 一键安装RKE2(国内源)
curl -sfL https://rancher-mirror.rancher.cn/rke2/install.sh | INSTALL_RKE2_MIRROR=cn sh -
# 启动服务
systemctl enable rke2-server.service && systemctl start rke2-server.service
提示:安装过程约 5-20 分钟(视网络情况),可通过
journalctl -fu rke2-server实时查看日志。
3. 验证集群状态
安装完成后,拷贝 Kubernetes 工具及配置文件,方便后续操作:
mkdir -p /root/.kube
#集群配置文件
cp /etc/rancher/rke2/rke2.yaml /root/.kube/config
#拷贝命令行工具
cp /var/lib/rancher/rke2/bin/{ctr,kubectl} /bin
执行以下命令,确认节点与核心组件正常运行:
#查看节点状态(应显示Ready)
kubectl get node
#查看系统Pod(所有kube-system命名空间下的Pod应为Running状态)
kubectl get pod -n kube-system
至此,K8S 集群 RKE2 已部署完成,接下来将通过 GPU Operator 接入显卡资源,为大模型运行提供算力支撑。
部署 GPU Operator
1. 提前准备国内镜像(解决 NFD 镜像拉取问题)
由于node-feature-discovery(NFD)镜像默认仓库在国外,需提前通过国内镜像站下载并打标签:
export CONTAINERD_ADDRESS=/run/k3s/containerd/containerd.sock
ctr -n k8s.io images pull registry.cn-hangzhou.aliyuncs.com/smallqi/node-feature-discovery:v0.17.2
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/smallqi/node-feature-discovery:v0.17.2 registry.k8s.io/nfd/node-feature-discovery:v0.17.2
2. 安装 Helm
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh
3. 配置 GPU Operator 安装参数
创建gpu-values.yaml,指定所有组件使用国内镜像仓库(避免拉取国外镜像失败):
cat > gpu-values.yaml << EOF
toolkit:
env:
- name: CONTAINERD_SOCKET
value: /run/k3s/containerd/containerd.sock
- name: CONTAINERD_RUNTIME_CLASS
value: nvidia
- name: CONTAINERD_SET_AS_DEFAULT
value: "true"
version: v1.17.1-ubuntu20.04
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
validator:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
operator:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
initContainer:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
driver:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
manager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
devicePlugin:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
dcgmExporter:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
gfd:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
migManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
vgpuDeviceManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
vfioManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
driverManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
EOF
4. 一键安装 GPU Operator
# 添加NVIDIA Helm仓库并更新
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
# 安装GPU Operator(指定版本和配置文件,无需修改参数)
helm install gpu-operator -n gpu-operator --create-namespace \
nvidia/gpu-operator --version=v25.3.0 -f gpu-values.yaml
提示:等待约 3-5 分钟,通过
kubectl get pod -n gpu-operator确认所有 Pod 状态为Running。
5. 配置 RKE2 默认容器运行时
配置 RKE2 默认使用 nvidia 作为容器运行时
cat > /etc/rancher/rke2/config.yaml << EOF
disable:
- rke2-ingress-nginx #禁用默认Ingress,会与Rainbond网关冲突
system-default-registry: registry.cn-hangzhou.aliyuncs.com # 国内镜像仓库
default-runtime: nvidia #指定 nvidia 为默认容器运行时
EOF
# 重启RKE2使配置生效
$ systemctl restart rke2-server.service
# 等待5分钟,确保所有系统Pod重新启动完成
6. 验证 GPU 算力调度
创建测试 Pod,验证 GPU 是否正常被 K8s 识别和使用:
# 生成测试YAML(运行CUDA示例程序)
cat > cuda-sample.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: registry.cn-hangzhou.aliyuncs.com/zqqq/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04
resources:
limits:
nvidia.com/gpu: 1 # 声明使用1张GPU
EOF
# 部署测试Pod
$ kubectl apply -f cuda-sample.yaml
查看日志(成功标志):
$ kubectl logs -f cuda-vectoradd
# 输出包含以下内容则表示GPU调度正常:
[Vector addition of 50000 elements]
...
Test PASSED #CUDA程序运行通过
Done
至此,GPU 资源已成功接入 RKE2 集群,已经可以在 K8S 集群内实现 GPU 调度。
部署 Rainbond
1. 添加 Rainbond Helm 仓库
helm repo add rainbond https://chart.rainbond.com
helm repo update
2. 配置集群网络参数
创建 values.yaml,指定集群入口 IP 和节点信息:
cat > values.yaml << EOF
Cluster:
gatewayIngressIPs: 14.103.241.65 # 填写服务器公网 IP 或负载均衡 IP
nodesForGateway:
- externalIP: 14.103.241.65 # 节点公网 IP
internalIP: 10.64.0.2 # 节点内网 IP
name: iv-ydu8hg737ks6iplmb2ks # 节点名称(通过 kubectl get node 查看)
nodesForChaos:
- name: iv-ydu8hg737ks6iplmb2ks # 节点名称(通过 kubectl get node 查看)
containerdRuntimePath: /run/k3s/containerd # 指向 RKE2 的容器运行时路径
EOF
3. 一键安装 Rainbond
helm install rainbond rainbond/rainbond --create-namespace -n rbd-system -f values.yaml
验证安装:
kubectl get pod -n rbd-system # 观察名称含 rbd-app-ui 的 Pod 状态
# 当状态显示 Running 且 Ready 为 1/1 时,说明安装完成(约 5-8 分钟)
访问界面:
通过配置的 gatewayIngressIPs 地址访问,格式:http://10.0.0.5:7070。
部署 Ollama
1. 通过 Rainbond 可视化界面安装 Ollama
登录后点击创建应用,选择从应用市场创建,在开源应用商店搜索关键词 ollama 并点击安装
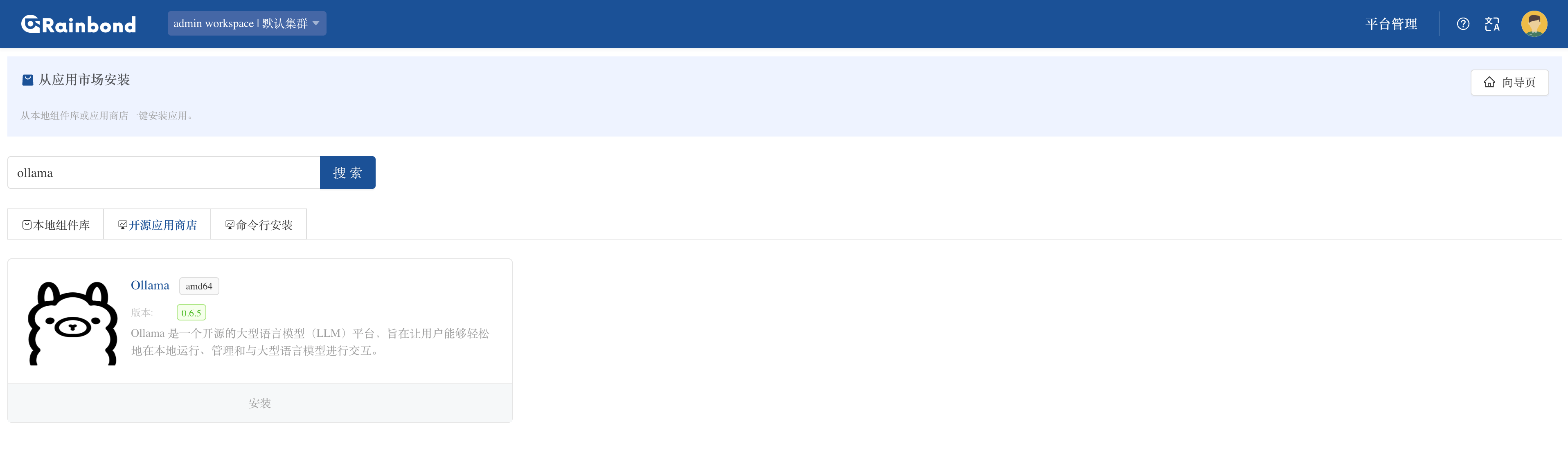
Rainbond 会自动拉取 Ollama 镜像并部署(镜像大小约 1.2GB)
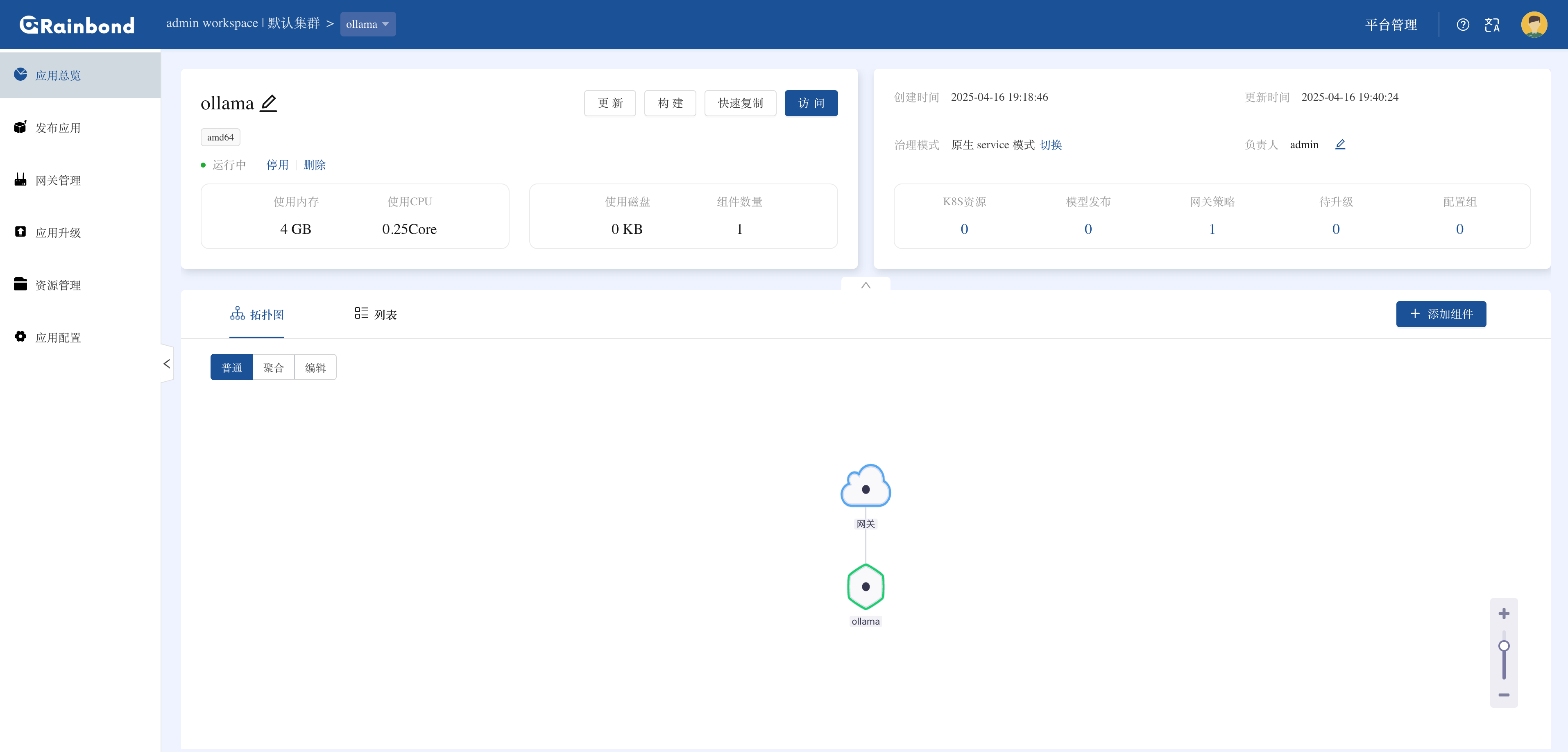
2. 按需分配计算资源
安装完成后,进入 Ollama 组件详情页,点击其他设置调整资源配额:
- CPU / 内存:建议根据模型规模设置(如 deepseek R1 14B 版本至少 12 核 + 32GB 内存),本例中暂时不限制(设置
0表示使用节点默认资源) - GPU 资源:在
limits中添加nvidia.com/gpu: 1(声明使用 1 张 GPU)。
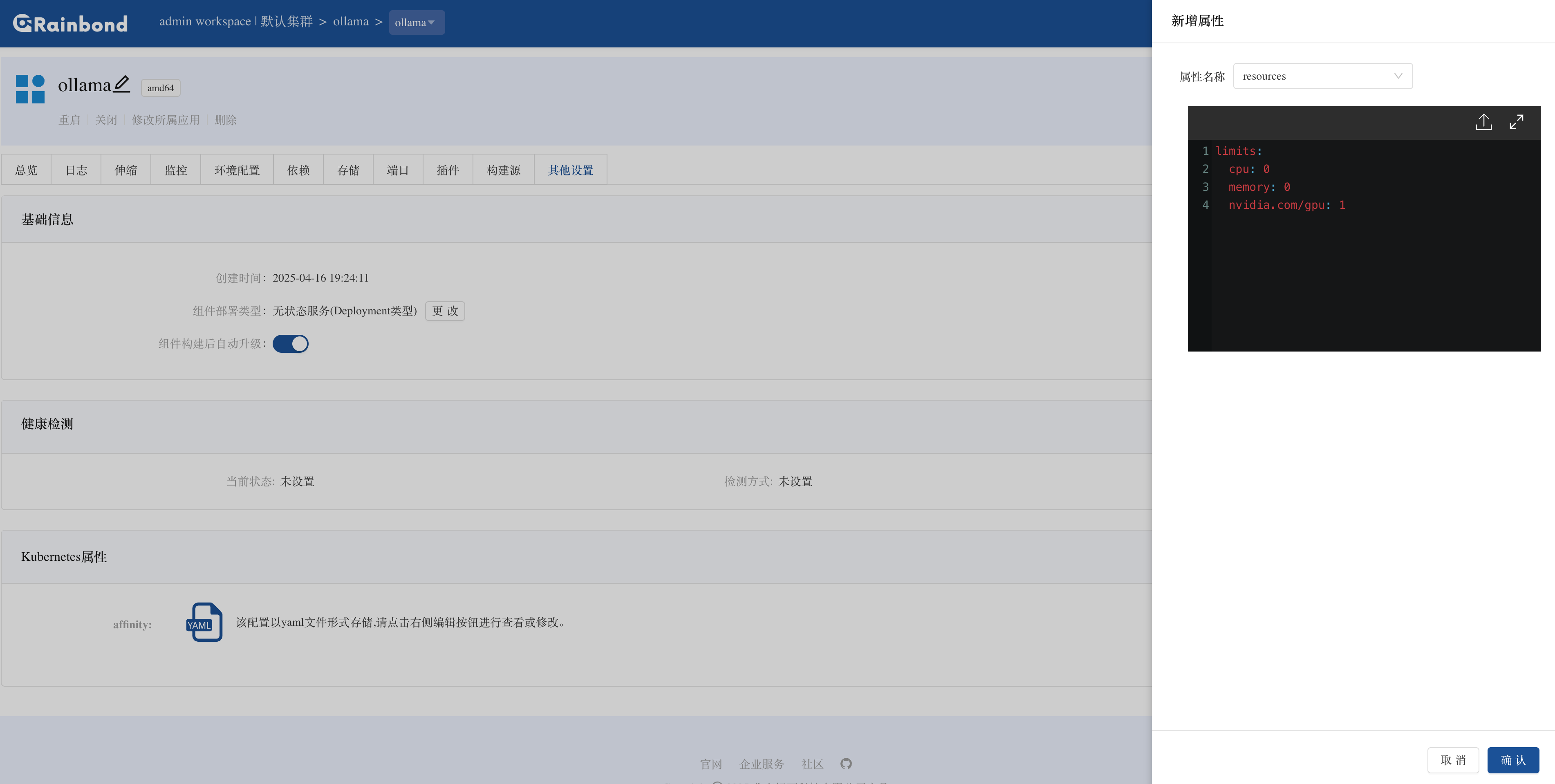
limits:
cpu: 0
memory: 0
nvidia.com/gpu: 1
保存配置后,点击左上角的重启按钮,等待 Ollama 组件重新启动使资源配置生效。等待约 1 分钟,组件状态恢复为绿色(Running)即可开始使用。
资源配置参考表(根据模型参数选择):
| 模型版本 | CPU 核心 | 内存要求 | 硬盘空间 | GPU 显存(推荐) |
|---|---|---|---|---|
| 1.5B | 4+ | 8GB+ | 3GB+ | 非必需(CPU 推理) |
| 7B/8B | 8+ | 16GB+ | 8GB+ | 8GB+(如 RTX 3070) |
| 14B | 12+ | 32GB+ | 15GB+ | 16GB+(如 RTX 4090) |
| 32B+ | 16+/32+ | 64GB+/128GB+ | 30GB+/70GB+ | 24GB+/ 多卡并行(如 A100) |
部署 DeepSeek R1
1. 通过 Web 终端启动模型服务
在 Rainbond 界面中进入 Ollama 组件详情页,点击右上角Web 终端进入命令行模式(需确保浏览器允许 WebSocket 连接)。 执行 Ollama 官方提供的模型启动命令(以 32B 版本为例):
ollama run deepseek-r1:32b
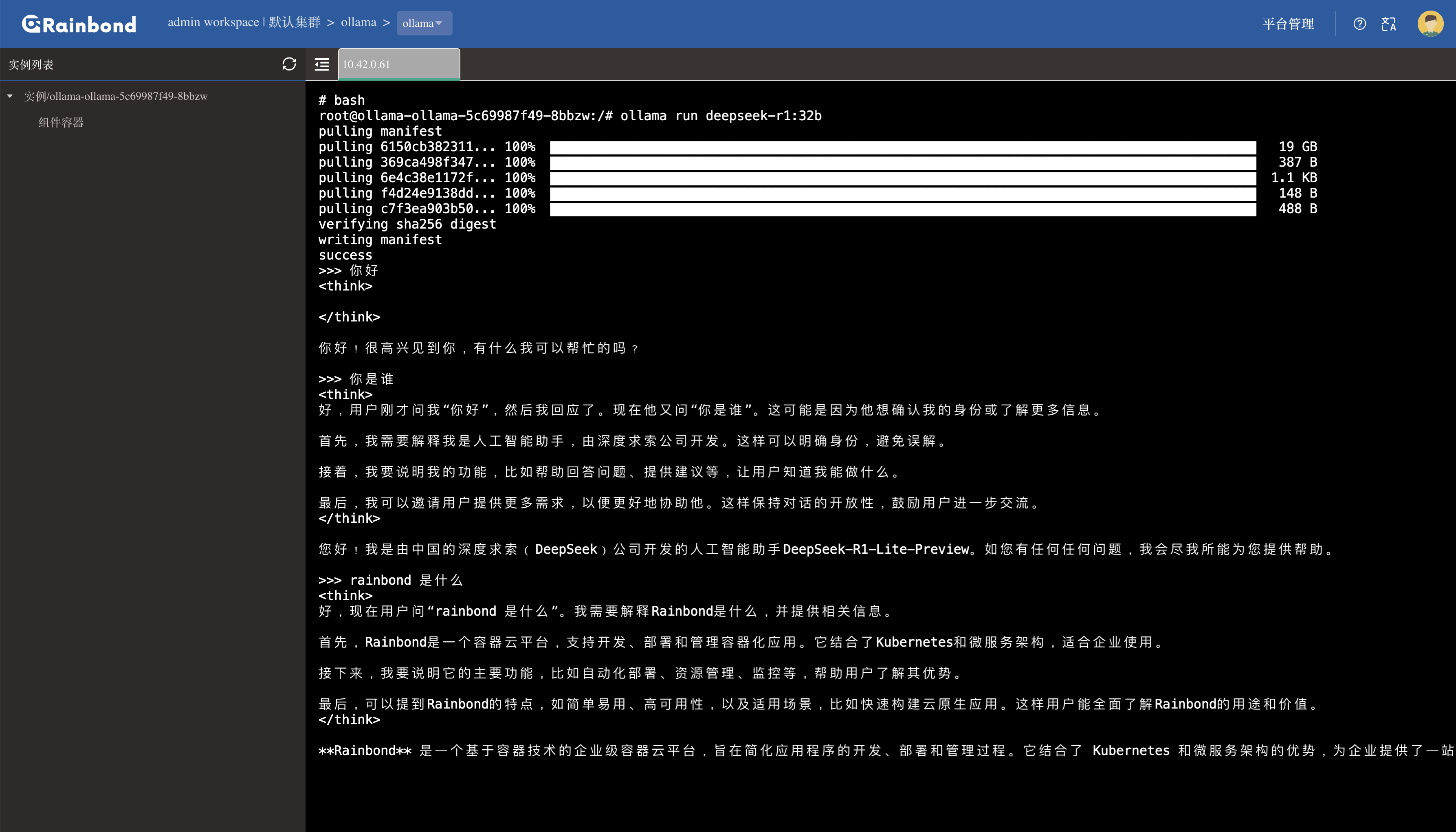
提示:若终端无响应,检查集群 WebSocket 地址是否可达:进入 平台管理 -> 集群 -> 编辑集群信息,复制 WebSocket 地址。在本地浏览器或 Postman 中测试该地址连通性。
2. 配置模型访问端口
在 Ollama 组件详情页中,找到端口设置项:
-
将默认的 HTTP 协议修改为 TCP
-
复制生成的访问地址(格式为
http://你的服务器IP:随机端口,如http://10.0.0.5:30000)。
注意:若使用域名访问,请在网关管理中绑定您的域名。

接入到 Chatbox 使用
1. 下载并安装 Chatbox
从 Chatbox 官方网站 下载对应平台的客户端(支持 Windows/macOS/Linux),完成安装后启动应用。
2. 添加 Ollama API 地址
进入 Chatbox 设置界面(点击左上角菜单 -> 设置 -> 模型管理):
- 点击添加自定义模型,选择Ollama类型
- 在地址栏粘贴 Rainbond 中获取的访问地址(如
http://10.0.0.5:30000),点击保存 - 系统会自动识别已部署的模型(如
deepseek-r1:32b),无需手动配置参数。

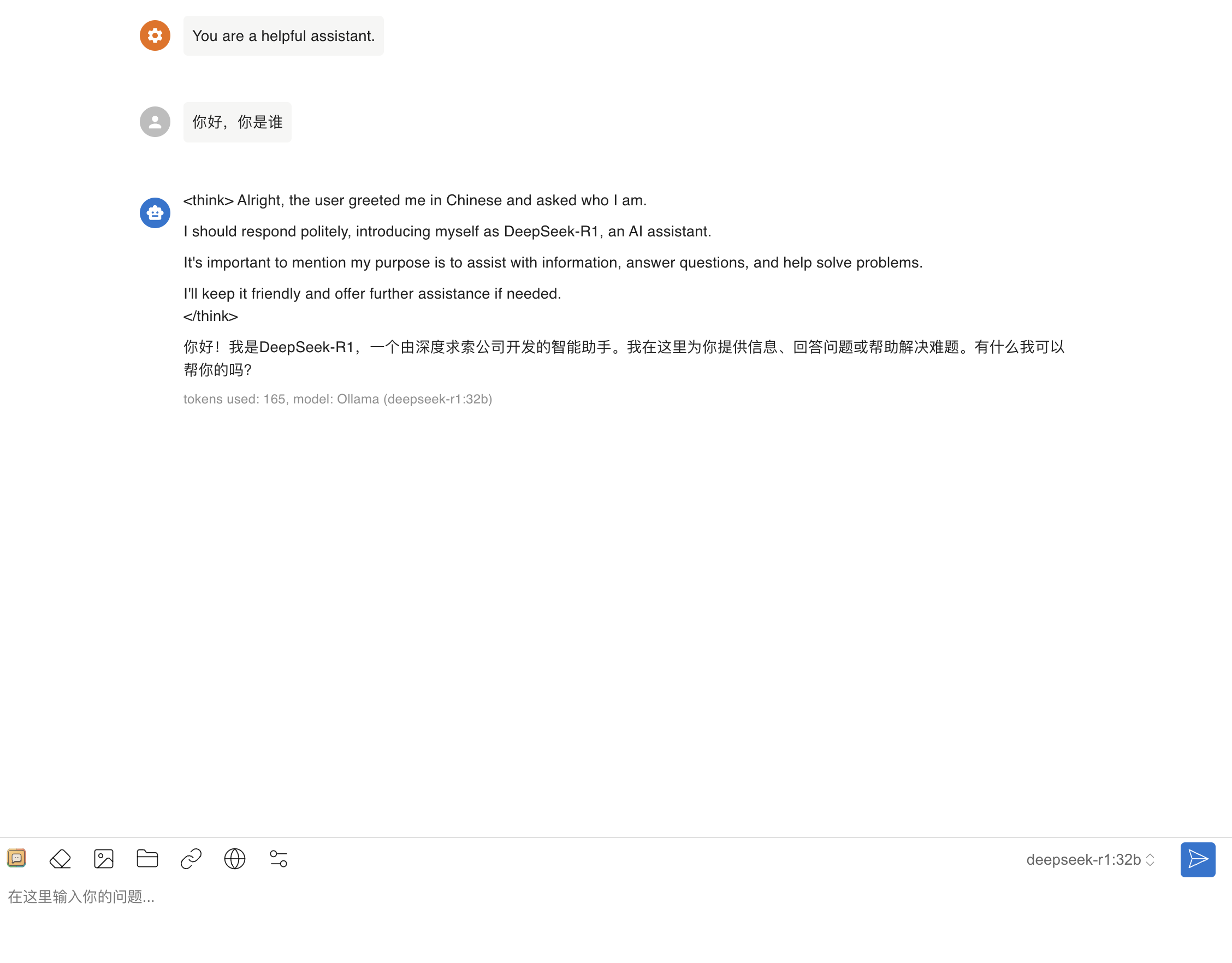
3. 开始对话
返回主界面,选择刚刚添加的 DeepSeek R1 模型,即可进入聊天窗口:
- 输入问题,点击发送
- 模型会实时返回响应,支持流式输出和历史对话记录查看。
最后
通过 Ollama、RKE2、Rainbond 与 GPU Operator 的高效组合,1 小时内即可完成 Deepseek 大模型的私有化部署。这仅仅是大模型私有部署的第一步,后续可依托 Rainbond 的快速开发能力,通过微服务构建、可视化编排等功能,轻松实现业务系统与大模型的深度集成,让企业在安全可控的本地化环境中,灵活调用大模型能力,加速 AI 应用落地。