不想先学 Kubernetes,团队怎么跑通第一个云原生试点?
· 阅读需 6 分钟
很多团队并不是不认可 Kubernetes,而是在真正开始推进时发现,第一步太重了。
常见情况是:
- 开发团队希望更快上线应用
- 运维团队希望平台标准化
- 管理者知道云原生是方向
- 但团队没有足够时间,先把 Kubernetes 全学一遍,再开始交付业务
于是问题就出现了:
不是方向不对,而是真正落地之前,团队先被复杂度挡住了。
很多团队并不是不认可 Kubernetes,而是在真正开始推进时发现,第一步太重了。
常见情况是:
于是问题就出现了:
不是方向不对,而是真正落地之前,团队先被复杂度挡住了。
还在手搓 K8s 离线安装包?你该升级装备了!
对于运维和开发工程师来说,离线环境部署 Kubernetes往往是一场噩梦。
当你兴致勃勃准备大干一场时,现实通常是这样的:
有没有一种工具,能像在线安装一样丝滑,把 K8s 集群和管理平台一次性端进离线机房?
今天,我们要向大家推荐一款神器 ROI (Rainbond Offline Installer)
ROI 是 Rainbond 团队专为完全离线环境打造的一站式部署工具。
它的目标很简单:让离线环境下的云原生平台交付,变得像 apt-get install 一样简单。
无论你是需要在无网的物理机房交付项目,还是在很多安全限制的内网做 POC,ROI 都能让你事半功倍。
ROI 不止安装 K8s。它提供了一个包含所有依赖的大礼包。
忘掉那些几百行的 Ansible 脚本吧。ROI 的操作逻辑简单到令人发指:
roi up,集群就好了。很多朋友为了离线装 K8s 费尽周折,但装好 K8s 后,如何让不懂 K8s 的开发人员也能用起来? 这才是更大的挑战。
使用 ROI,你在获得一个标准 K8s 集群的同时,还免费获得了一套强大的不用懂 Kubernetes 的开源容器平台 —— Rainbond。
Rainbond 能为你做什么?
ROI + Rainbond,不仅解决了怎么装的问题,更解决了怎么用的问题。
如果你想从解决方案角度判断“纯离线安装、离线交付、麒麟 V10 / ARM 部署、x86 到 ARM 迁移”应该先看哪条路径,建议进入 离线 / 信创 / 国产化专题,完全离线环境可以直接从 纯离线环境安装 开始。
眼见为实,让我们看看用 ROI 部署有多简单。
# 下载 ROI 工具
curl -o roi https://get.rainbond.com/roi/roi-amd64 && chmod +x roi
# 一键下载所有离线资源
./roi download
拿到 offline-packages 目录后,通过 U 盘或光盘拷贝到内网服务器。
单机部署下默认会部署 NFS Server,你需要手动安装,如 yum -y install nfs-utils。
TODO:未来会支持自动部署
# 无需任何配置,直接起飞
./roi up
只需编写一个简单的 cluster.yaml:
hosts:
- name: node-1
address: 172.16.0.134
internalAddress: 172.16.0.134
user: root
password: root
- name: node-2
address: 172.16.0.135
internalAddress: 172.16.0.135
user: root
password: root
- name: node-3
address: 172.16.0.136
internalAddress: 172.16.0.136
user: root
password: root
# Role assignment
roleGroups:
etcd: [node-1, node-2, node-3]
master: [node-1, node-2]
worker: [node-1, node-2, node-3]
nfs-server: [node-1]
rbd-gateway: [node-2, node-3]
rbd-chaos: [node-2, node-3]
# Storage configuration
storage:
nfs:
enabled: true
sharePath: /nfs-data/k8s
storageClass:
enabled: true
# Database configuration - MySQL with master-slave replication
database:
mysql:
enabled: true
masterPassword: "RootPassword123!"
replicationPassword: "ReplPassword123!"
# Rainbond configuration
rainbond:
version: v6.4.0-release
然后执行:
./roi up -f cluster.yaml
✅ 安装完成!
终端会直接输出访问地址。打开浏览器,你不仅拥有了一个 Ready 状态的 K8s 集群,更拥有了一个功能完备的 Rainbond 控制台。
离线交付不再难,用 ROI 重新定义你的部署效率。
Kubernetes 已经成为了云原生时代基础设施的事实标准,越来越多的应用系统在 Kubernetes 环境中运行。Kubernetes 已经依靠其强大的自动化运维能力解决了业务系统的大多数运行维护问题,然而还是要有一些状况是需要运维人员去手动处理的。那么和传统运维相比,面向 Kubernetes 解决业务运维问题是否有一些基本思路,是否可以借助其他工具简化排查流程,就是今天探讨的主题。
首先有必要明确一点,什么样的问题算是 Kubernetes 领域的业务系统问题。Kubernetes 目前已经是云原生时代各类 “上云” 业务系统所处运行环境的事实标准。
我们假定你已经拥有了一套健壮的 Kubernetes 环境,业务系统的运行状态不会受到底层运行环境异常的影响,当业务系统出现问题时,Kubernetes 也可以正确的收集到业务系统的运行状态信息。
有了这假定条件之后,我们就可以将业务系统问题约束在业务从部署到正常运行起来这一时间区间内。所以本文探讨的业务系统问题的范畴�包括:
解决这一类的问题的意义是显而易见的,因为将业务系统运行起来是一种最基础的需求。具备一套健壮的 Kubernetes 运行环境或者是编写了一套业务系统代码都不会为我们产生直接的价值。只有将业务系统代码运行到一个稳定的环境中,面向最终用户提供服务时才会为我们产生真正的价值。
值得庆幸的是,解决这类问题多半只需要我们踩一次坑。对于大多数全新的业务系统而言,部署到 Kubernetes 环境中去时,所可能遭遇的问题只需要被处理一次。一旦部署完成,业务系统就可以专注于迭代功能,不断循环完成发布过程即可,顺利进入了一个循环往复的 CI/CD 流程之中。
除去基础需求这一显而易见的意义,我们也会探讨如何降低解决这类问题的难度,解决问题难度的降低本身也具有意义。云原生时代,我们倡导每个开发人员都能够掌控自己的业务系统,这种掌控也对开发人员提出了新的要求,即掌控 Kubernetes 的使用。这有点将运维层面的工作附加给开发人员的意思,实际推广过程并不顺利。为了便于开发人员使用 Kubernetes 来部署与调试自己开发的业务系统,企业可以选择云原生应用平台来降低开发人员使用 Kubernetes 的门槛,Rainbond 就是这样一款不用懂 Kubernetes 的开源容器平台,其易用性的特点降低了开发人员的学习门槛,同时能够为业务系统赋能。
正常情况下,负责部署业务系统的工作人员是通过声明式的配置文件来定义业务系统的,其中的关键部分称之为规约(Spec)。这些规约字段通过格式严苛的 Yaml 类型配置文件来定义,正确填写其中的键与值需要庞杂的 Kubernetes 知识的保障。而掌握配置文件的格式,以及配置中的内容,往往是开发人员学习原生 Kubernetes 的首个陡峭门槛。
原生的使用方式中,kubectl 命令行工具会为这些配置文件提供严苛的校验机制,然而在校验无法通过时,能够给出的提示却并不是很友好。
以一份非常简单的 Yaml 配置文件为例:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: my-nginx
name: my-nginx
namespace: default
spec:
replicas: 1
selector:
matchLabels:
app: my-nginx
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- image: nginx
name: nginx
env:
- name: DEMO_GREETING
value: "true" # 此处必须用引号扩起来,因为这是个 string 类型
securityContext:
privileged: true # 此处必须不能使用引号,因为这是个 bool 类型
配置中有两个 true 值,然而其中一个必须使用引号,而另一个则不是,这对一些新手而言并不是很友好。而加载这份配置文件的错误版本时,系统给出的报错虽然可以定位问题,但是交互体验更加不友好。
$ kubectl apply -f my-deployment.yaml
Error from server (BadRequest): error when creating "my-deployment.yaml": Deployment in version "v1" cannot be handled as a Deployment: v1.Deployment.Spec: v1.DeploymentSpec.Template: v1.PodTemplateSpec.Spec: v1.PodSpec.Containers: []v1.Container: v1.Container.Env: []v1.EnvVar: v1.EnvVar.Value: ReadString: expects " or n, but found t, error found in #10 byte of ...|,"value":true}],"ima|..., bigger context ...|ainers":[{"env":[{"name":"DEMO_GREETING","value":true}],"image":"nginx","name":"nginx"}]}}}}
像这样的问题,在类似 Rainbond 这样的开源容器平台中,则不会出现。产品设计之时,就已经屏蔽了一些常见输入错误,用户不需要关注传入值的类型问题,平台会自行进行转换。
平台会自动为环境变量添加引号以匹配 string 类型:

以开启/关闭来体现 bool 类型:

对于一些特殊输入,也会进行合理校验,提供的反馈信息更加人性化:

借助这些功能,即使是小白用户也可以正确的定义业务系统的规格。
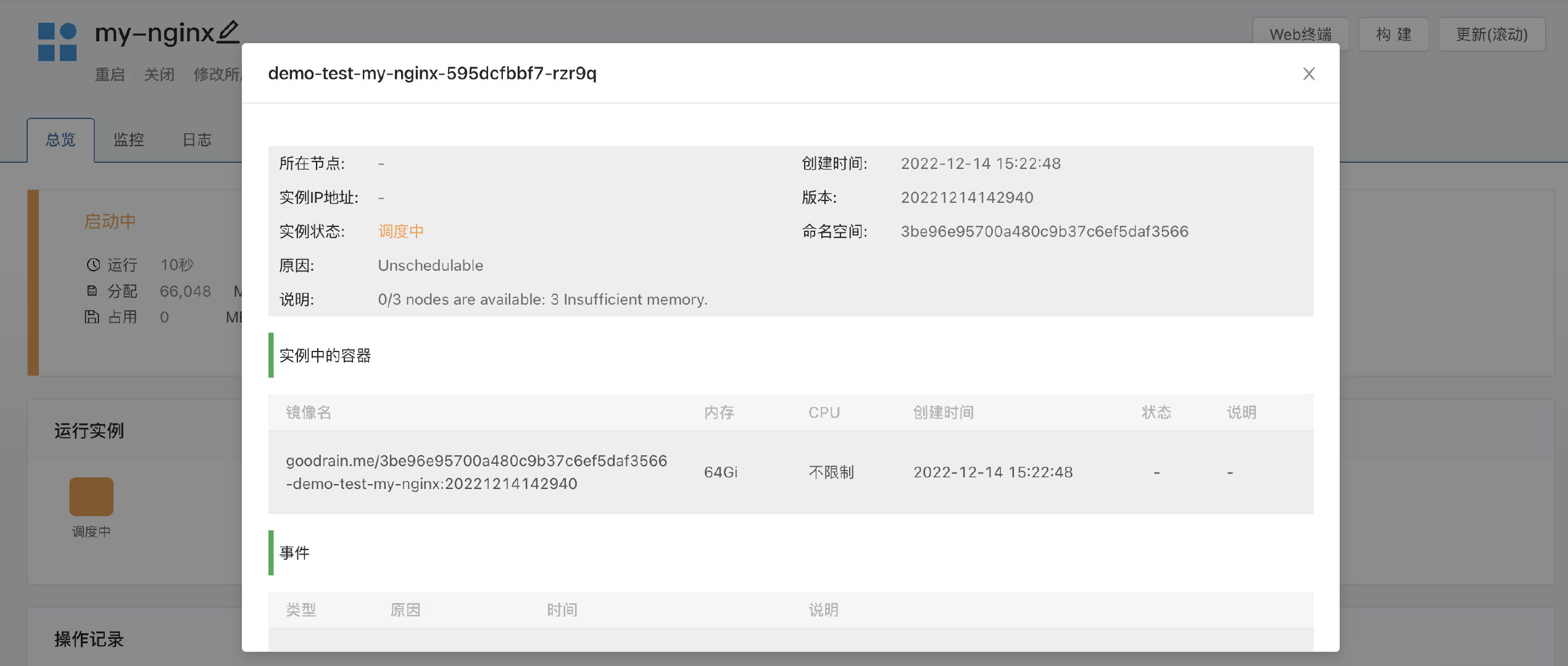
业务系统的规格定义完成后,就可以提交给 Kubernetes 系统了,下一步,Kubernetes 将会借助自身调度机制,将业务系统分配到合适的宿主机上运行起来。在进行调度的过程中,业务系统会在一小段时间内处于 Pending(待定的) 的状态,然而长期处于 Pending 状态则说明调度过程中出现了问题。
Kubernetes 以事件的形式,记录了业务系统在进入运行状态之前的每一个步骤。一旦出现了 Warning 甚至更严重级别的事件时,就说明业务系统的部署过程受阻了。了解如何查看这些事件,并理解其背后代表的意义,对于排查调度问题非常有帮助。
能够让业务系统长期处于 Pending 状态的常见问题包括:镜像拉取失败、资源不足等。使用原生 Kubernetes 时,难免和命令行打交道,来获取对应 Pod 的事件信息。
$ kubectl describe pod <podName> -n <nameSpace>
当所有的计算节点都没有足够的内存资源来调度业务系统的 Pod 时,事件信息是这样的:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling <unknown> default-scheduler 0/3 nodes are available: 3 Insufficient memory.
而拉取镜像失败则是这样的:
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning Failed 26s kubelet, cn-shanghai.10.10.10.25 Error: ErrImagePull
Normal BackOff 26s kubelet, cn-shanghai.10.10.10.25 Back-off pulling image "nginx_error"
Warning Failed 26s kubelet, cn-shanghai.10.10.10.25 Error: ImagePullBackOff
Normal Pulling 15s (x2 over 29s) kubelet, cn-shanghai.10.10.10.25 Pulling image "nginx_error"
对事件列表的解读,是需要较深厚的 Kubernetes 领域知识的。开发者需要从事件列表中找到关键词,进而采取正确的行动来解决问题。
在 Rainbond 中,已经事先想到了降低问题排查成本的需求,用户点击代表有问题的业务系统 Pod 的方块,即可了解其详细信息。在这个页面中,浓缩了核心问题的说明、当前 Pod 的状态以及说明,可以帮助用户极快的定位问题。
当业务系统完成了调度过程后,Kubernetes 系统就会将业务系统对应的 Pod 启动起来,到这里,已经距离业务系统对外提供服务很近了。但是不要掉以轻心,Pod 启动时是有可能遭遇运行异常的。
一般情况下,正常运行中的 Pod 是体现 Running 状态的,开发人员可以通过命令行的方式获取其状态:
$ kubectl get pod <podName> -n <nameSpace>
但是如果处于异常状态,则可能得到以下结果:
NAME READY STATUS RESTARTS AGE
demo-test-my-nginx-6b78f5fc8-f9rkz 0/1 CrashLoopBackOff 3 86s
CrashLoopBackOff 是一种异常的状态,除此之外还可能出现一些其他的异常状态,比如:OOMkilled 、 Evicted等。对于每一种错误类型的处理也不尽相同。这需要非常丰富的 Kubernetes 问题排查经验。
比如对于 CrashLoopBackOff 这种异常状态,它意味着 Pod 中的某个容器无法正常运行,代码运行过程中遭遇了不可容忍的问题,报错退出了。正确的处理,是应该查询问题 Pod 的日志,了解业务代码层面的异常。
$ kubectl logs -f <podName> -n <nameSpace>
这种排查的思路是可以固化的,与所部署的业务系统本身没有关系,所以 Rainbond 做了一些人性化的设计,如果业务系统的 Pod 处于这种异常状态并被操作记录捕获,那么用户点击这条异常的操作记录,即可直接跳转到日志页面查看问题日志。这种设计隐式的为用户提供了排查思路,即使用户自己并没有意识到应该这么做。

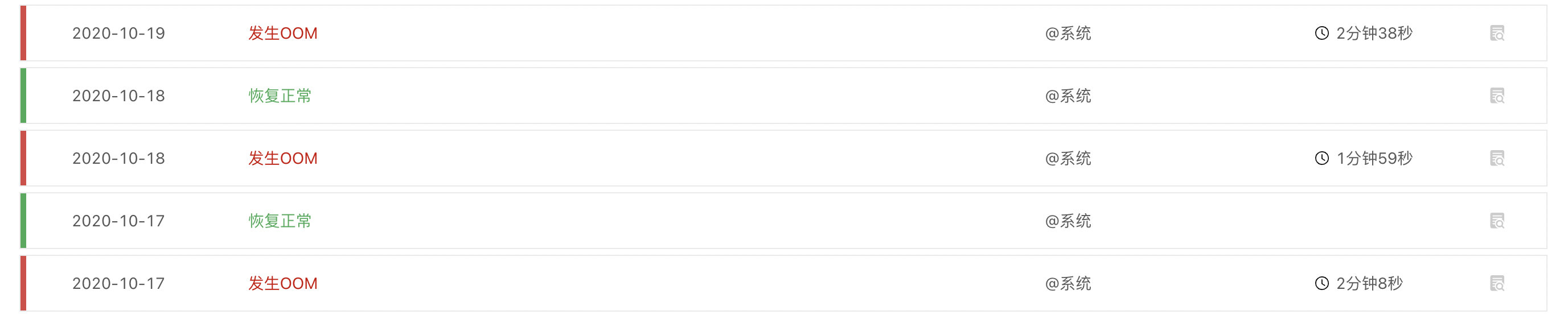
还有一种特殊类型的运行过程中问题需要注意。 CrashLoopBackOff 这种问题一般出现在 Pod 启动时,用户很容易就可以捕捉到,而类似于 OOMkilled 这种问题一般是在业务系统运行很久之后,才会出现。这种问题不容易被用户捕捉到,这是因为 Kubernetes 会自动重启出现这类问题的业务系统 Pod 来自动恢复,从而导致问题的湮没。
Rainbond 会自动记录这一类异常状态,并留下相应日志供后续的分析,了解到到底是 Pod 中的哪个容器导致了内存泄露。
基于原生 Kubernetes 进行业务系统的各阶段问题排查,需要开发人员对 Kubernetes 知识体系有较深入的了解,并且能够接受命令行交互式操作体验。这无形中提升了对开发人员的技术要求,也对其强加了一些运维领域的工作内容,使云原生落地体验受阻。开发人员也不应该拿到可以直接操作 Kubernetes 的命令行权限,这不符合安全规定。
为了能够让开发人员合理的调试业务系统,选用一款开源容器平台将会是个正确的选择。Rainbond 的设计者,深入了解过开发人员的诉求,通过为开发人员提供简单易用的功能,以及人性化的设计,让开发人员调试业务系统变得事半功倍。
上次折腾完 DeepSeek 的本��地私有化部署后,心里就一直琢磨着:能不能给咱们 Rainbond 的用户再做点实用的东西?毕竟平时总收到反馈说文档查找不够方便,要是能有个 AI 文档助手该多好。正想着呢,搭建本地知识库的想法就冒了出来 —— 既能解决实际需求,又能把技术落地成真正有用的工具,这不就是两全其美的事嘛!尤其是想到企业场景里,知识库往往涉及业务流程、技术方案甚至客户数据,数据安全可是头等大事,本地化部署带来的数据不出本地、自主可控优势,简直是刚需中的刚需。
第一个跳进脑海的方案就是 Dify。作为最近一直在关注的工具,它在文档处理上的灵活性特别吸引我 —— 既能像搭积木一样定制问答逻辑,又能完美适配本地化部署环境,天生契合既要智能高效,又要安全合规的需求。于是赶紧搜了一波资料,发现确实有不少可参考的实践经验,但系统从零搭建的教程却不多。想着可能有不少朋友和我一样,既想拥有专属的知识库系统,又苦于没有清晰的入门指引,索性决定把自己的实践过程整理出来。
接下来这篇文章,就打算用最接地气的方式,手把手带你从 0 到 1 搭建一套专属的本地知识库系统。无论你是想优化企业内部文档检索(不用担心敏感数据上传云端的风险),还是像我一样想为用户打造更智能的文档服务,都能跟着步骤一步步实现。咱们不卖关子,直接上干货。
Dify 是一款开源的大语言模型(LLM) 应用开发平台。它融合了后端即服务(Backend as Service)和 LLMOps 的理念,使开发者可以快速搭建生产级的生成式 AI 应用。即使你是非技术人员,也��能参与到 AI 应用的定义和数据运营过程中。
Dify 官方提供了使用 Docker Compose 部署的方式,如下:
$ git clone https://github.com/langgenius/dify.git --branch 0.15.3
$ cd dify/docker
$ cp .env.example .env
$ docker-compose up -d
你可能会遭遇无法获取 Github 代码、Docker 镜像等问题,需要挂🪜解决。
对于不熟悉 K8s 的伙伴,又想在 K8s 中安装 Dify,可以使用 Rainbond 来部署。Rainbond 是一个不用懂 Kubernetes 的开源容器平台,支持通过可视化界面管理容器化应用,提供应用市场一键部署、源码构建等能力,帮助用户在不接触 K8s 底层的前提下,轻松实现应用的生产级部署与运维。
免费试用 Rainbond Cloud(零门槛快速体验)
如果你想零成本快速上手云原生部署,推荐直接体验 Rainbond Cloud(点击注册 https://run.rainbond.com,新用户即享免费额度)—— 无需自备服务器或配置复杂环境,注册登录后,在云端环境中一键部署 Dify,5 分钟内即可开启 AI 应用开发。
私有化本地部署(企业级可控性首选)
如果需要将 Dify 部署在自有服务器或数据中心(满足数据本地化、合规性要求),Rainbond 提供极简私有化部署方案,无需手动编写 K8s 配置,10 分钟内即可完成生产级环境搭建:
curl -o install.sh https://get.rainbond.com && bash ./install.sh
等待几分钟后,通过 http://IP:7070 访问 Rainbond 并注册登录。
通过应用市场一键部署 Dify
创建应用并选择通过应用市场部署,在开源应用商店中搜索Dify ,点击一键安装。
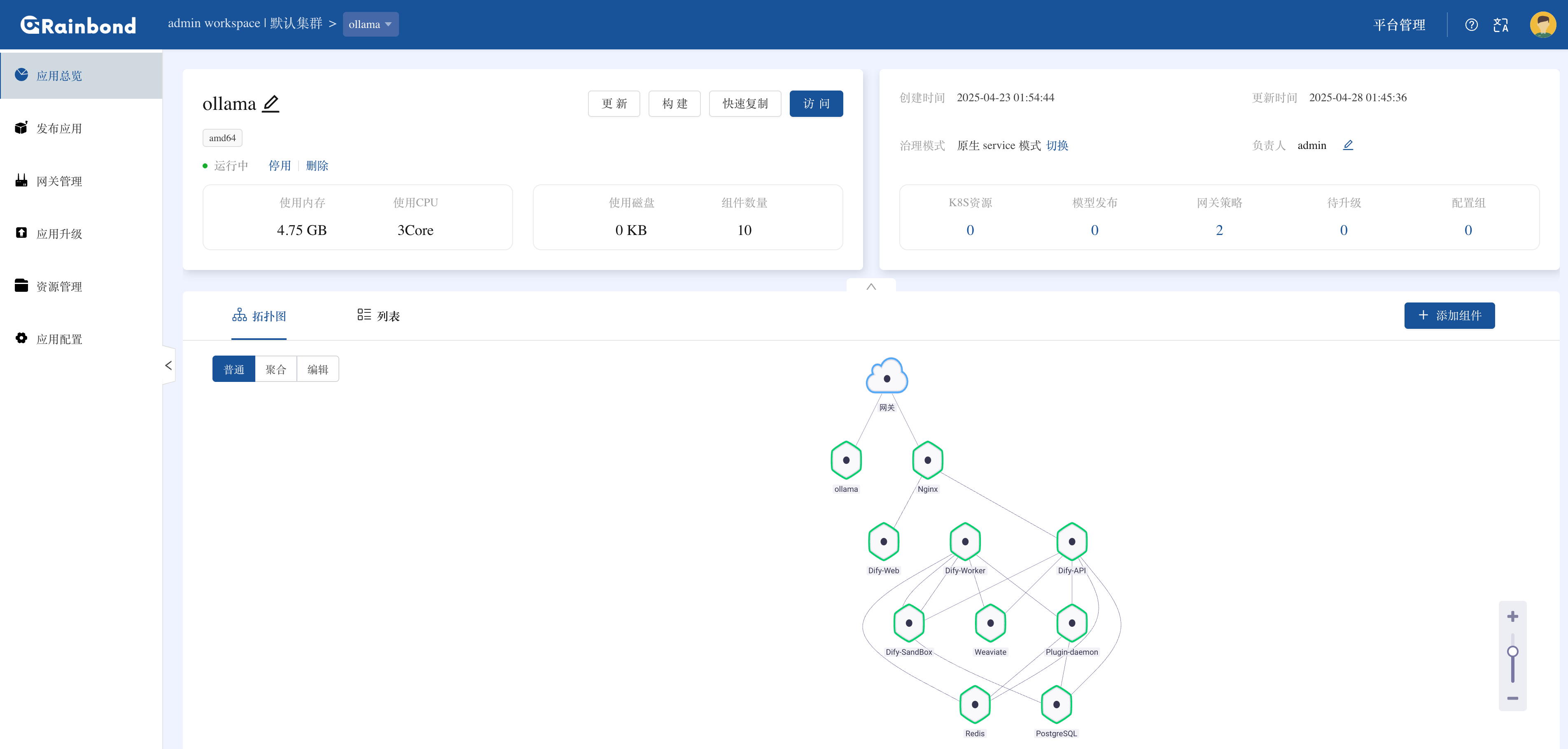
等待拓扑图中的组件颜色全部变为绿色则代表部署成功。
由于应用模板给每个组件分配的资源比较少,只能保障基本运行,在实测过程中索引 200 个文档左右 Worker 等服务就发生了 OOM。需要在安装完成后手动调整下相关组件的资源,比如 API、Worker、Plugin、Sandbox 组件的资源配额。进入到组��件内 -> 伸缩,修改资源为 500m、1G ,具体根据实际情况来调整。
点击访问按钮即可通过平台生成的域名访问 Dify 可视化界面,注册即可开始 AI 应用开发之旅。
关于如何在本地部署 DeepSeek R1 大模型可以参考我写的上一篇文章 K8S 部署 Deepseek 要 3 天?别逗了!Ollama+GPU Operator 1 小时搞定,同时在哔哩哔哩也有视频。
Embedding 模型就像一个语义转换器:把我们写的文字、上传的文档这些人类能看懂的内容,变成机器能计算的数字指纹(向量)。比如怎么备份文件和文件备份步骤,这两句话意思差不多,经过模型处理后,生成的向量也很接近,这样机器就能知道它们是同一个意思,而不是只看字是不是一样。
在咱们的知识库里,上传的资料必须先通过这个模型转换成向量,存到专门的数据库里。这样当用户用自然语言提问时,系统不是傻乎乎地匹配关键词,而是真正理解问题的意思,从数据库里精准找到最相关的内容。比如问API 调用报错怎么解决,系统能直接定位到文档里讲错误处理的部分,而不是只返回带API和报错字眼的零散段落,这一步就像给知识库建了一个语义索引,是让 AI 能读懂咱们私有数据的关键。
使用 Ollama 部署本地的 Embedding 模型:
进入 Rainbond 的 Ollama 组件内,进入 Web 终端执行如下命令:
ollama pull bge-m3
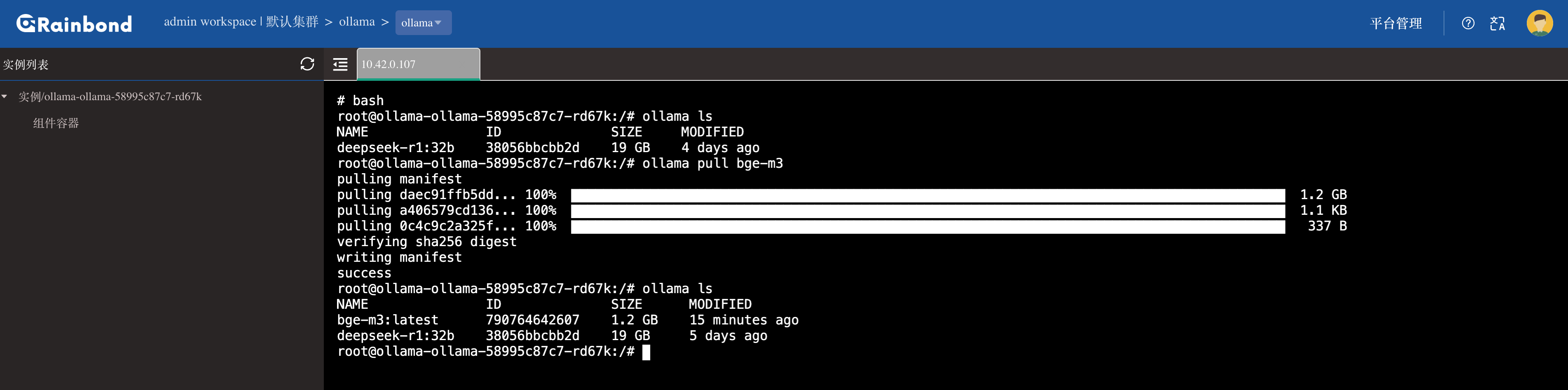
为啥选 BGE-M3?主要因为它是专为中文检索场景定制的选手,背靠中科院团队研发,天生自带中文语义理解 Buff。你也可��以直接在 Ollama 里搜索其他 Embedding 模型。
进入 Dify 页面后,点击右上角头像 -> 设置 -> 模型供应商,安装 Ollama。插件安装可能需要点时间,如未成功请再次安装。
分别对接本地的 LLM 和 Text Embedding 模型相关信息。我这里填写的是 Ollama 内网地址,因为我的 Dify 和 Ollama 部署在一个 Rainbond 集群内,就可以通过内网访问;内网地址可在 Ollama 组件内 -> 端口查看到对内服务的访问地址,如下:
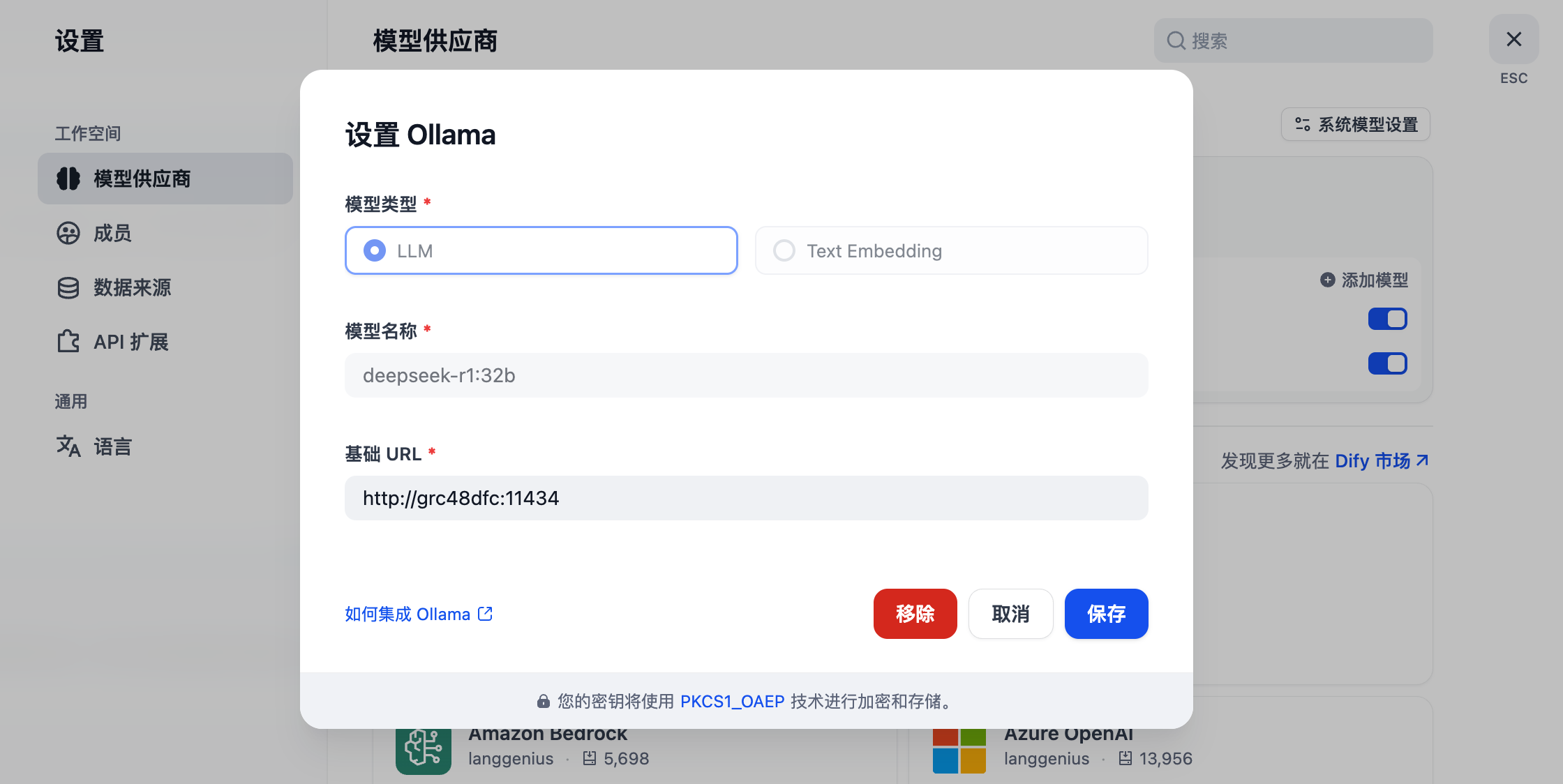
踩坑:保存后模型没有添加,我又添加了好几次,最后我等了10分钟左右插件才加载好,前面重复添加的几个都出来了-。-
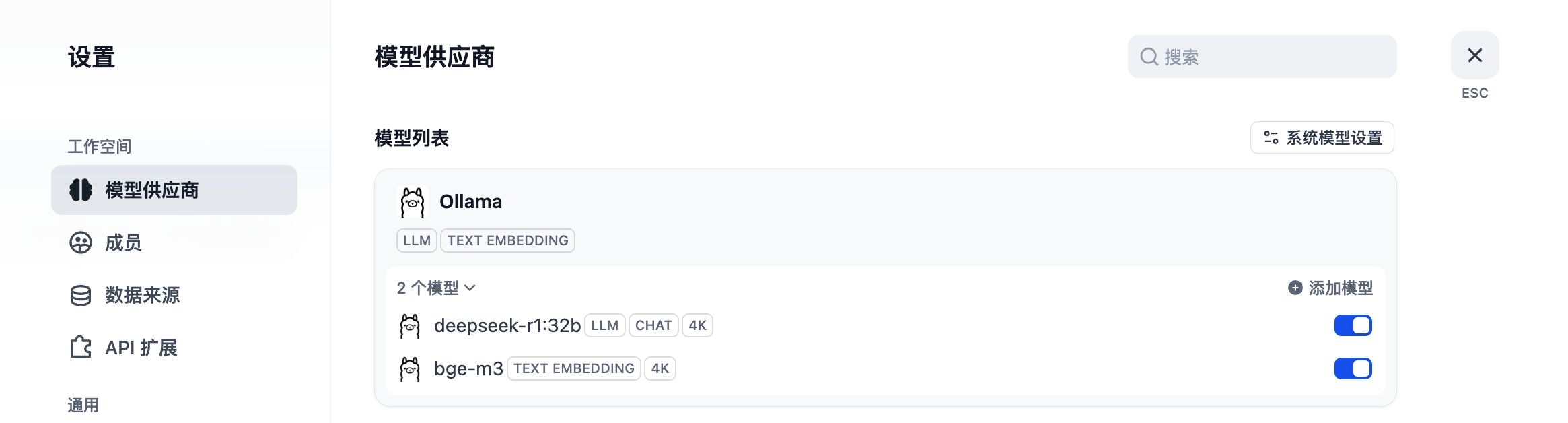
配置系统默认模型。
点击上方的知识库按钮,创建一个新的知识库,上传本地的文档并下一步。
这里是对文档进行分段与清洗,这里都默认就可以了,具体可以参考 Dify 知识库文档。
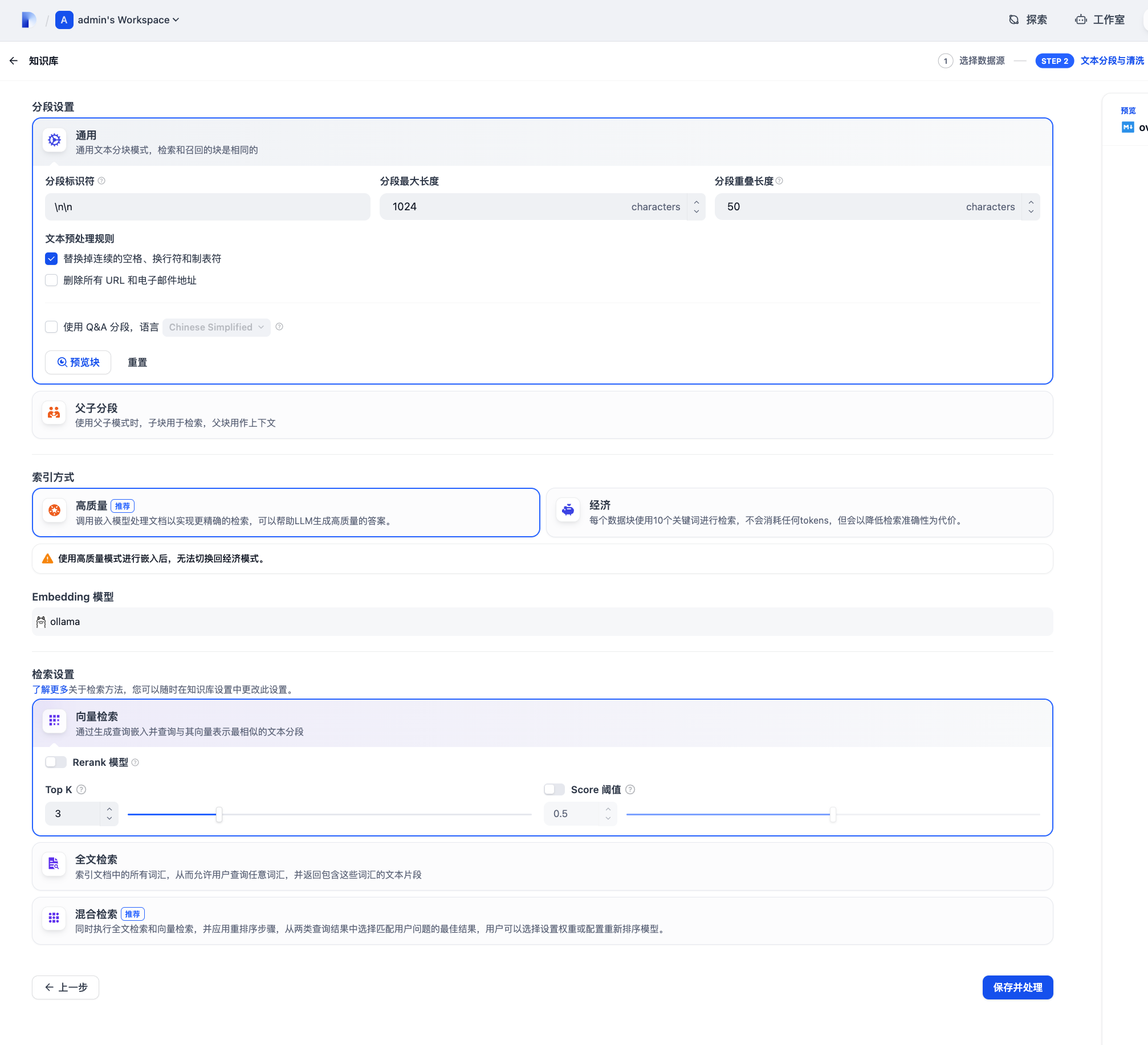
模型记得选择我们上面配置的 bpe-m3 Embedding 模型。
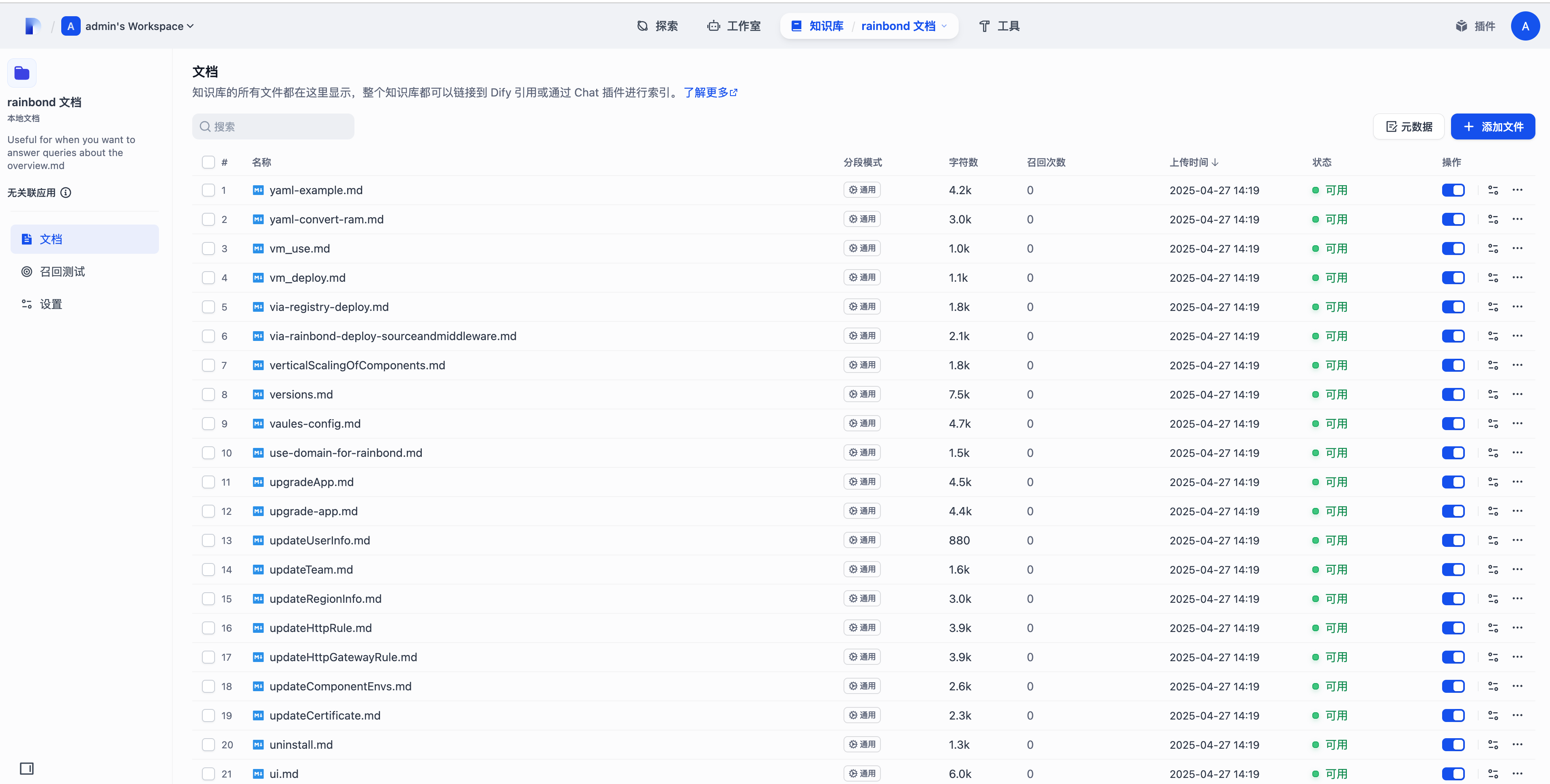
等待所有文档的状态变为可用即可进行下一步。
首先我们创建一个聊天助手应用。
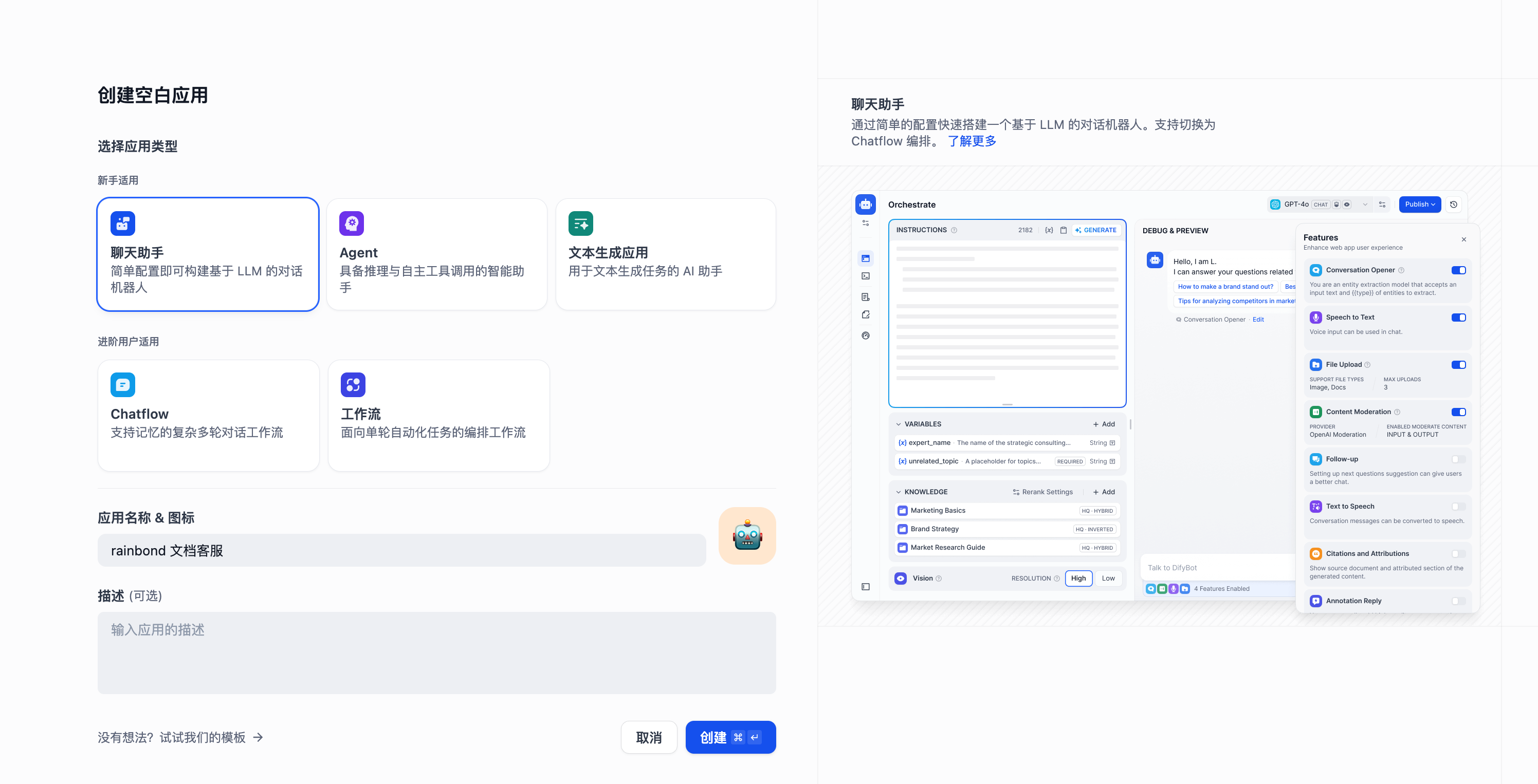
添加我们上面创建的知识库
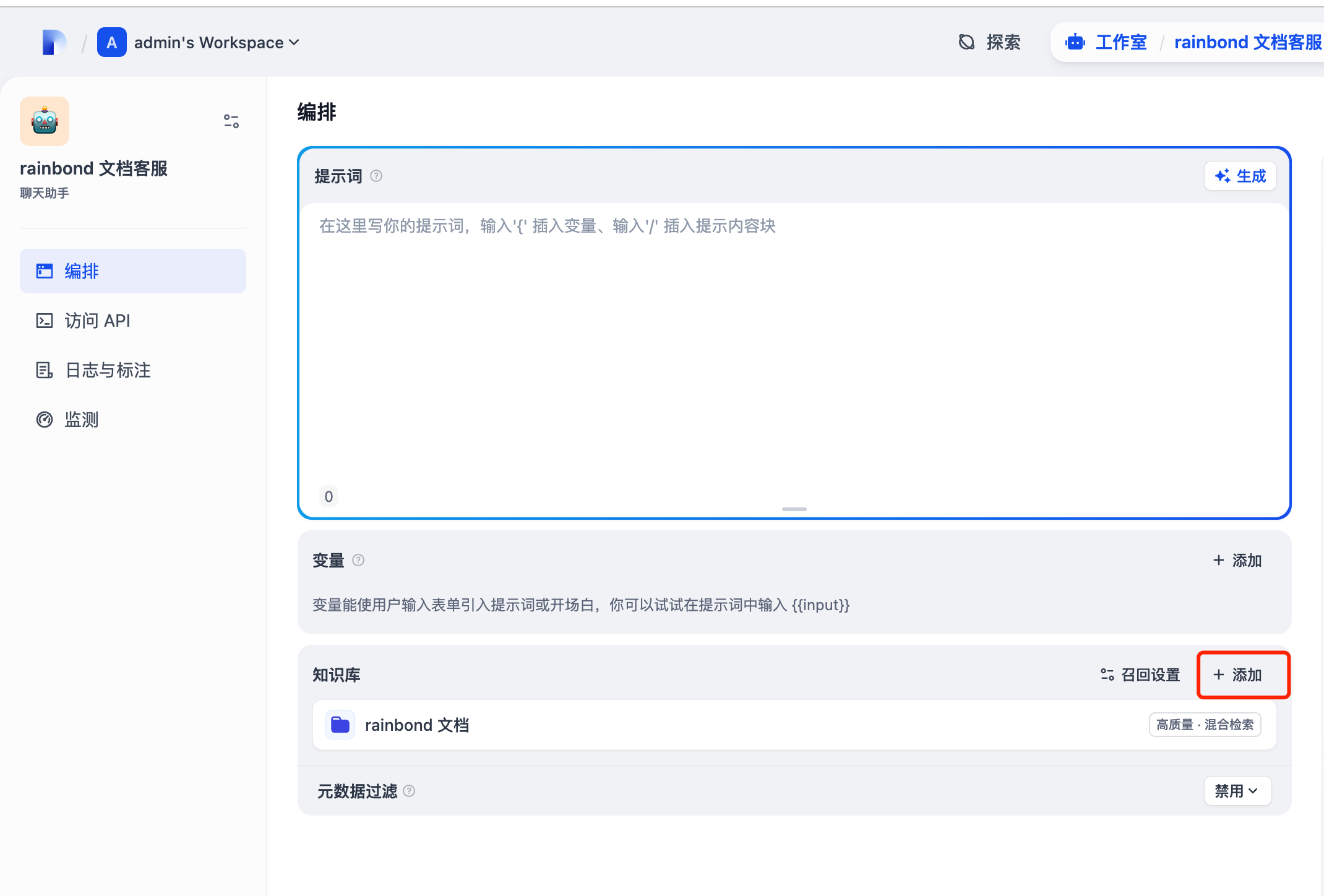
点击右上角的发布,再点击运行。
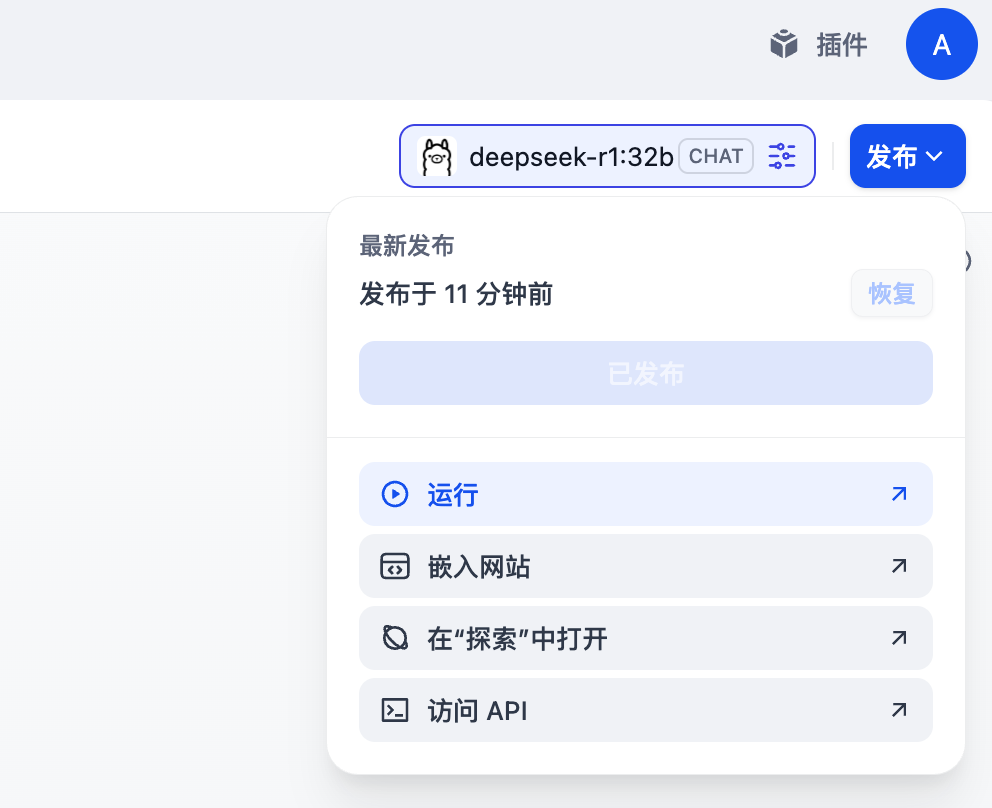

可以说效果还是比较不错的。如果感觉回答的效果还不满意,可以参考文档对召回参数进行调整。
到这儿,一个能读懂企业私有文档、数据完全本地化可控的 AI 知识库就搭好了!从部署 Dify 到配置 Embedding 模型,再到上传文档、创建聊天助手,每一步都是围绕让技术落地为实际需求设计的;既解决了传统文档检索的低效问题,又用本地化部署守住了数据安全的底线。把复杂的架构变成人人能用的工具,让代码和文档真正服务于业务。
如果你在搭建过程中遇到资源调整、模型适配等细节问题,别忘了回到文中看看踩坑提示;如果想进一步优化问答效果,Dify 的召回参数配置、Rainbond 的资源调度策略都有很大探索空间。现在,你可以试着让这个专属的 AI 助手回答文档问题,也可以把它分享给团队小伙伴,让知识真正流动起来。
后续我还会分享更多本地化 AI 应用的实操经验,如果你对某个环节想深入了解,或者有新的需求场景,欢迎在评论区留言。咱们下期折腾再见~👋
最近一年我都在依赖大模型辅助工作,比如 DeepSeek、豆包、Qwen等等。线上大模型确实方便,敲几个字就能生成文案、写代码、做表格,极大提高了效率。但对于企业来说:公司内部数据敏感、使用外部大模型会有数据泄露的风险。
尤其是最近给 Rainbond 开源社区的用户答疑时,发现大家对大模型私有化部署有需求,都希望把大模型部署到企业内网,既能按需定制优化,又能保障安全合规。
网上教程虽多,但大多零散且偏向极客操作,真正能落地到生产环境的少之又少。稍微花了点时间,终于跑通了一套全链路解决方案:
这套组合对开发者和企业来说,意味着效率与安全的双重升级:开发者无需处理模型环境和集群配置,Ollama+Rainbond 让部署从 “写代码” 变成 “点鼠标”,专注业务逻辑;企业则实现数据本地化,通过 RKE2 安全策略和 Rainbond 权限管理满足合规要求,搭配 GPU Operator 提升硬件利用率,让私有化部署既简单又高效。
接下来的教程,我会从服务器准备到环境搭建再到大模型部署,拆解每个关键步骤。无论你是想搭建企业专属大模型服务,还是探索本地化 AI 应用,跟着教程走,都能少走弯路,快速落地一个安全、高效、易管理的大模型部署方案。
首先需要一台干净的 GPU 服务器,推荐硬件配置如下(以 NVIDIA A100 为例):
先以单节点集群为例快速落地演示。
创建私有镜像仓库配置(Rainbond 默认的私有镜像仓库)
mkdir -p /etc/rancher/rke2
cat > /etc/rancher/rke2/registries.yaml << EOF
mirrors:
"goodrain.me":
endpoint:
- "https://goodrain.me"
configs:
"goodrain.me":
auth:
username: admin
password: admin1234
tls:
insecure_skip_verify: true
EOF
创建集群基础配置
cat > /etc/rancher/rke2/config.yaml << EOF
disable:
- rke2-ingress-nginx #禁用默认Ingress,会与Rainbond网关冲突
system-default-registry: registry.cn-hangzhou.aliyuncs.com # 国内镜像仓库
EOF
通过国内镜像加速安装,提升部署速度
# 一键安装RKE2(国内源)
curl -sfL https://rancher-mirror.rancher.cn/rke2/install.sh | INSTALL_RKE2_MIRROR=cn sh -
# 启动服务
systemctl enable rke2-server.service && systemctl start rke2-server.service
提示:安装过程约 5-20 分钟(视网络情况),可通过
journalctl -fu rke2-server实时查看日志。
安装完成后,拷贝 Kubernetes 工具及配置文件,方便后续操作:
mkdir -p /root/.kube
#集群配置文件
cp /etc/rancher/rke2/rke2.yaml /root/.kube/config
#拷贝命令行工具
cp /var/lib/rancher/rke2/bin/{ctr,kubectl} /bin
执行以下命令,确认节点与核心组件正常运行:
#查看节点状态(应显示Ready)
kubectl get node
#查看系统Pod(所有kube-system命名空间下的Pod应为Running状态)
kubectl get pod -n kube-system
至此,K8S 集群 RKE2 已部署完成,接下来将通过 GPU Operator 接入显卡资源,为大模型运行提供算力支撑。
由于node-feature-discovery(NFD)镜像默认仓库在国外,需提前通过国内镜像站下载并打标签:
export CONTAINERD_ADDRESS=/run/k3s/containerd/containerd.sock
ctr -n k8s.io images pull registry.cn-hangzhou.aliyuncs.com/smallqi/node-feature-discovery:v0.17.2
ctr -n k8s.io images tag registry.cn-hangzhou.aliyuncs.com/smallqi/node-feature-discovery:v0.17.2 registry.k8s.io/nfd/node-feature-discovery:v0.17.2
curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
&& chmod 700 get_helm.sh \
&& ./get_helm.sh
创建gpu-values.yaml,指定所有组件使用国内镜像仓库(避免拉取国外镜像失败):
cat > gpu-values.yaml << EOF
toolkit:
env:
- name: CONTAINERD_SOCKET
value: /run/k3s/containerd/containerd.sock
- name: CONTAINERD_RUNTIME_CLASS
value: nvidia
- name: CONTAINERD_SET_AS_DEFAULT
value: "true"
version: v1.17.1-ubuntu20.04
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
validator:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
operator:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
initContainer:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
driver:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
manager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
devicePlugin:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
dcgmExporter:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
gfd:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
migManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
vgpuDeviceManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
vfioManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
driverManager:
repository: registry.cn-hangzhou.aliyuncs.com/smallqi
EOF
# 添加NVIDIA Helm仓库并更新
helm repo add nvidia https://helm.ngc.nvidia.com/nvidia && helm repo update
# 安装GPU Operator(指定版本和配置文件,无需修改参数)
helm install gpu-operator -n gpu-operator --create-namespace \
nvidia/gpu-operator --version=v25.3.0 -f gpu-values.yaml
提示:等待约 3-5 分钟,通过
kubectl get pod -n gpu-operator确认所有 Pod 状态为Running。
配置 RKE2 默认使用 nvidia 作为容器运行时
cat > /etc/rancher/rke2/config.yaml << EOF
disable:
- rke2-ingress-nginx #禁用默认Ingress,会与Rainbond网关冲突
system-default-registry: registry.cn-hangzhou.aliyuncs.com # 国内��镜像仓库
default-runtime: nvidia #指定 nvidia 为默认容器运行时
EOF
# 重启RKE2使配置生效
$ systemctl restart rke2-server.service
# 等待5分钟,确保所有系统Pod重新启动完成
创建测试 Pod,验证 GPU 是否正常被 K8s 识别和使用:
# 生成测试YAML(运行CUDA示例程序)
cat > cuda-sample.yaml << EOF
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: registry.cn-hangzhou.aliyuncs.com/zqqq/cuda-sample:vectoradd-cuda11.7.1-ubuntu20.04
resources:
limits:
nvidia.com/gpu: 1 # 声明使用1张GPU
EOF
# 部署测试Pod
$ kubectl apply -f cuda-sample.yaml
查看日志(成功标志):
$ kubectl logs -f cuda-vectoradd
# 输出包含以下内容则表示GPU调度正常:
[Vector addition of 50000 elements]
...
Test PASSED #CUDA程序运行通过
Done
至此,GPU 资源已成功接入 RKE2 集群,已经可以在 K8S 集群内实现 GPU 调度。
helm repo add rainbond https://chart.rainbond.com
helm repo update
创建 values.yaml,指定集群入口 IP 和节点信息:
cat > values.yaml << EOF
Cluster:
gatewayIngressIPs: 14.103.241.65 # 填写服务器公网 IP 或负载均衡 IP
nodesForGateway:
- externalIP: 14.103.241.65 # 节点公网 IP
internalIP: 10.64.0.2 # 节点内网 IP
name: iv-ydu8hg737ks6iplmb2ks # 节点名称(通过 kubectl get node 查看)
nodesForChaos:
- name: iv-ydu8hg737ks6iplmb2ks # 节点名称(通过 kubectl get node 查看)
containerdRuntimePath: /run/k3s/containerd # 指向 RKE2 的容器运行时路径
EOF
helm install rainbond rainbond/rainbond --create-namespace -n rbd-system -f values.yaml
验证安装:
kubectl get pod -n rbd-system # 观察名称含 rbd-app-ui 的 Pod 状态
# 当状态显示 Running 且 Ready 为 1/1 时,说明安装完成(约 5-8 分钟)
访问界面:
通过配置的 gatewayIngressIPs 地址访问,格式:http://10.0.0.5:7070。
登录后点击创建应用,选择从应用市场创建,在开源应用商店搜索关键词 ollama 并点击安装
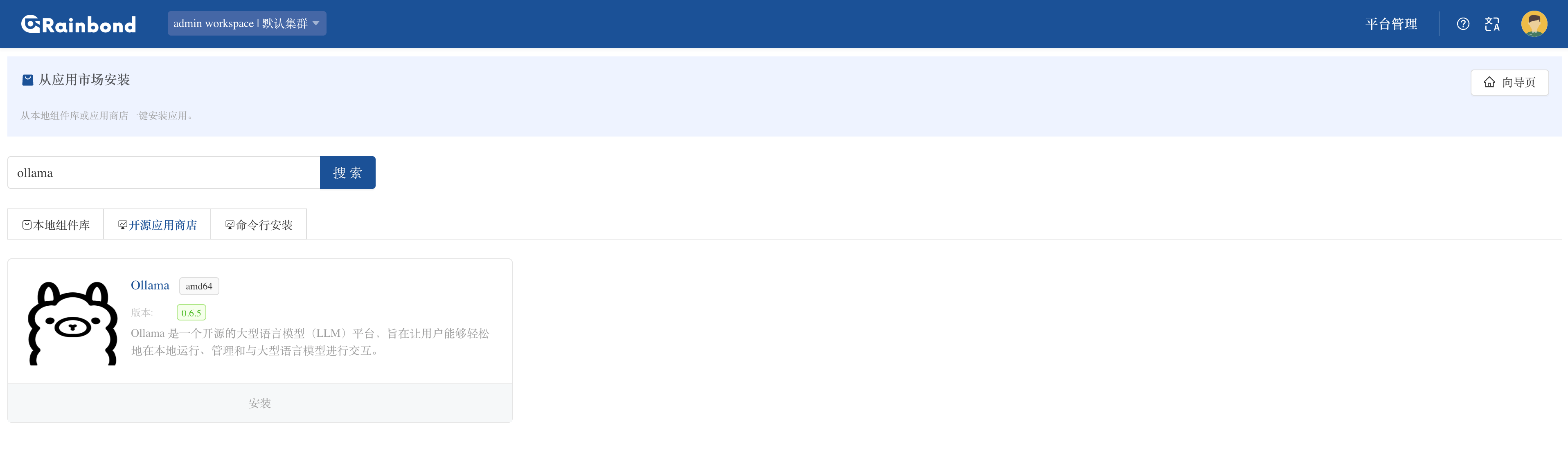
Rainbond 会自动拉取 Ollama 镜像并部署(镜像大小约 1.2GB)
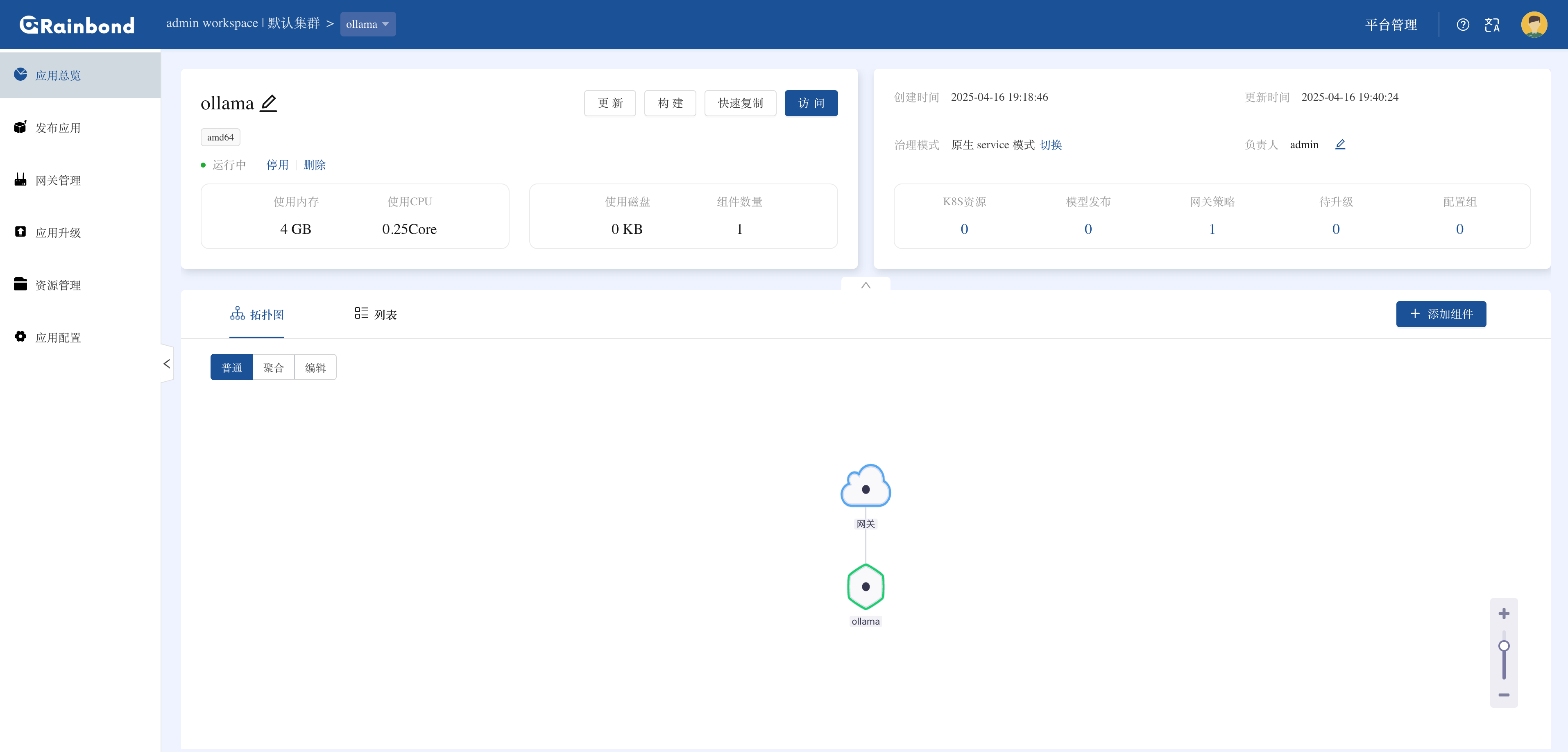
安装完成后,进入 Ollama 组件详情页,点击其他设置调整资源配额:
0 表示使用节点默认资源)limits 中添加 nvidia.com/gpu: 1(声明使用 1 张 GPU)。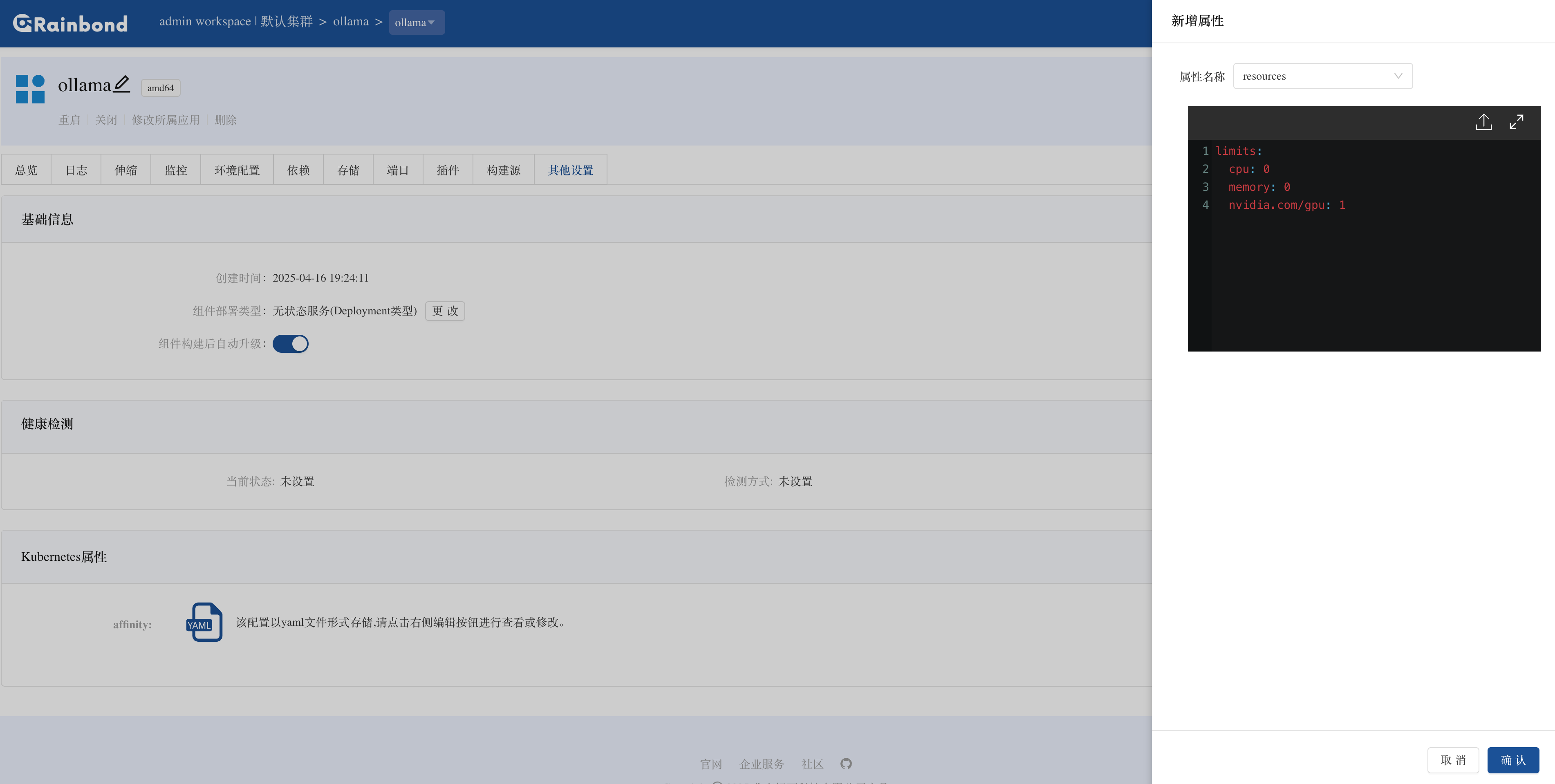
limits:
cpu: 0
memory: 0
nvidia.com/gpu: 1
保存配置后,点击左上角的重启按钮,等待 Ollama 组件重新启动使资源配置生效。等待约 1 分钟,组件状态恢复为绿色(Running)即可开始使用。
资源配置参考表(根据模型参数选择):
| 模型版本 | CPU 核心 | 内存要求 | 硬盘空间 | GPU 显存(推荐) |
|---|---|---|---|---|
| 1.5B | 4+ | 8GB+ | 3GB+ | 非必需(CPU 推理) |
| 7B/8B | 8+ | 16GB+ | 8GB+ | 8GB+(如 RTX 3070) |
| 14B | 12+ | 32GB+ | 15GB+ | 16GB+(如 RTX 4090) |
| 32B+ | 16+/32+ | 64GB+/128GB+ | 30GB+/70GB+ | 24GB+/ 多卡并行(如 A100) |
在 Rainbond 界面中进入 Ollama 组件详情页,点击右上角Web 终端进入命令行模式(需确保浏览器允许 WebSocket 连接)。 执行 Ollama 官方提供的模型启动命令(以 32B 版本为例):
ollama run deepseek-r1:32b
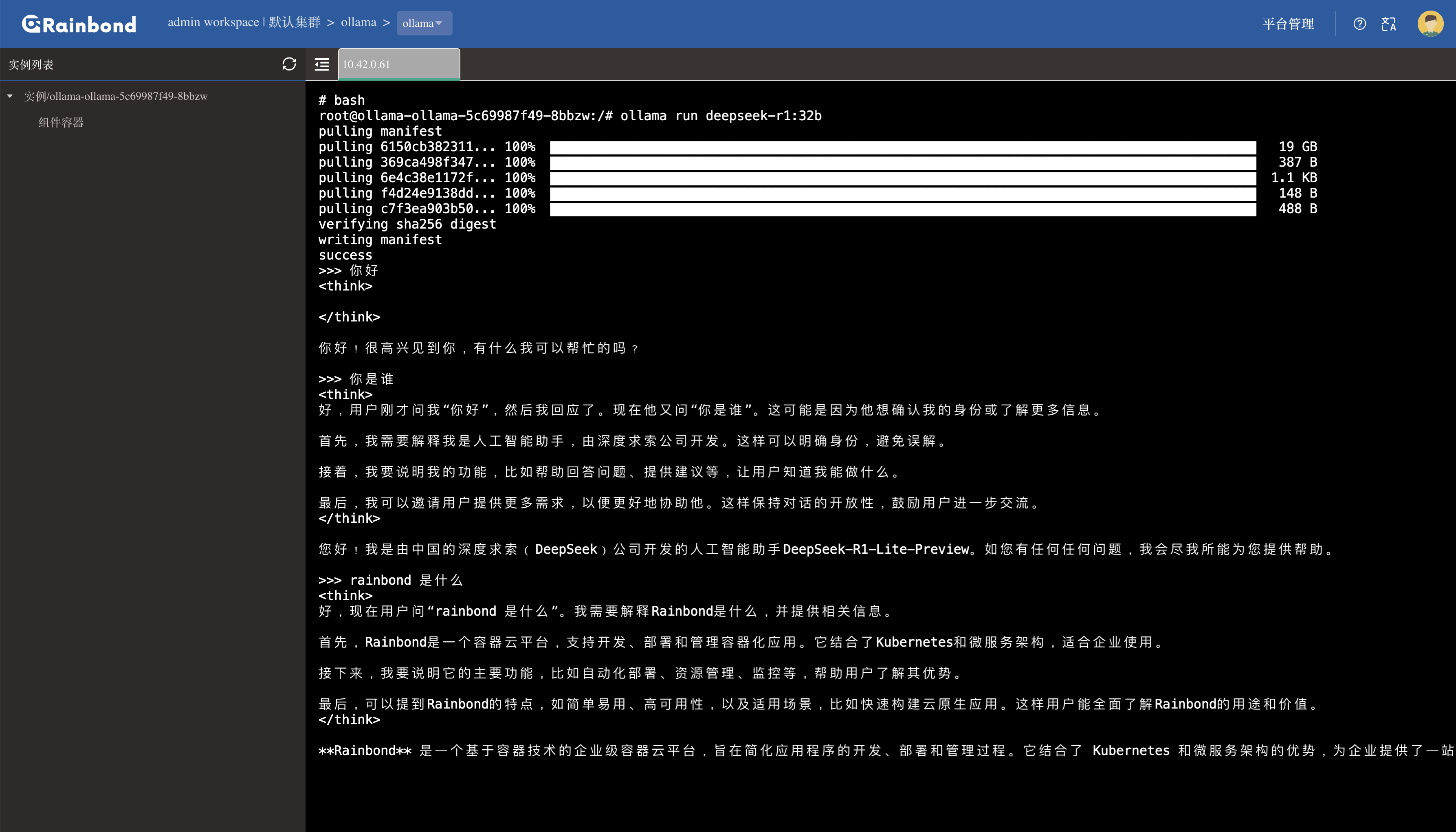
提示:若终端无响应,检查集群 WebSocket 地址是否可达:进入 平台管理 -> 集群 -> 编辑集群信息,复制 WebSocket 地址。在本地浏览器或 Postman 中测试该地址连通性。
在 Ollama 组件详情页中,找到端口设置项:
将默认的 HTTP 协议修改为 TCP
复制生成的访问地址(格式为 http://你的服务器IP:随机端口,如 http://10.0.0.5:30000)。
注意:若使用域名访问,请在网关管理中绑定您的域名。

从 Chatbox 官方网站 下载对应平台的客户端(支持 Windows/macOS/Linux),完成安装后启动应用。
进入 Chatbox 设置界面(点击左上角菜单 -> 设置 -> 模型管理):
http://10.0.0.5:30000),点击保存deepseek-r1:32b),无需手动配置参数。
返回主界面,选择刚刚添加的 DeepSeek R1 模型,即可进入聊天窗口:
通过 Ollama、RKE2、Rainbond 与 GPU Operator 的高效组合,1 小时内即可完成 Deepseek 大模型的私有化部署。这仅仅是大模型私有部署的第一步,后续可依托 Rainbond 的快速开发能力,通过微服务构建、可视化编排等功能,轻松实现业务系统与大模型的深度集成,让企业在安全可控的本地化环境中,灵活调�用大模型能力,加速 AI 应用落地。
在 AI 技术高速发展的今天,企业和开发者面临着将 AI 能力融入业务流程的迫切需求。从数据智能处理到自动化决策,传统工具要么缺乏 AI 原生支持,要么需要复杂的代码集成,难以兼顾效率与灵活性。n8n 作为一款明星级的开源工作流自动化平台,通过AI 节点可视化编排 + 代码深度扩展的独特模式,让任何人都能轻松构建智能工作流,成为连接 AI 技术与业务落地的桥梁。
n8n 是开源的 AI 原生工作流自动化平台。它将 AI 能力深度融入工作流编排,支持通过可视化节点拖拽调用主流 AI 服务(如 OpenAI、Hugging Face),同时允许开发者通过代码自定��义 AI 逻辑,实现从数据输入 → AI 处理 → 结果应用的全链路自动化。无论是非技术人员快速搭建智能流程,还是企业级复杂 AI 场景开发,n8n 都能提供高效解决方案。
主流 AI 服务原生集成:内置 OpenAI(GPT-3/4)、Anthropic(Claude)、Hugging Face(LLaMA、Stable Diffusion)、Midjourney 等节点,无需编写 API 代码即可实现:
文本生成:自动生成邮件回复、报告摘要、客服话术(如接收到用户咨询时,调用 GPT 节点生成初步回复草稿)。
多模态处理:图片上传 → Stable Diffusion 节点生成风格化图像 → 自动保存至云存储;语音文件 → Whisper 节点转文字 → NLP 节点提取关键信息。
数据分析:通过 Google Sheets 节点读取数据 → AI 节点自动分类 / 预测(如客户流失预警、销售趋势分析)。
可视化 AI 流程编排:通过拖放节点连接 AI 服务与业务系统,非技术人员也能快速搭建数据输入 → 智能分析 → 业务响应的闭环。
脚本节点嵌入自定义 AI 逻辑:在 JavaScript/Python 节点中调用本地 AI 库(如 PyTorch、spaCy)或第三方工具(如 LangChain),实现复杂智能处理:
私有模型集成:企业可加载自训练的 NLP 模型(如法律文档解析模型),对上传的 PDF 文件进行关键条款提取,结果自动填入 CRM 系统;
多模型串联:组合 GPT(意图识别)+ 自定义规则引擎(业务逻辑)+ Midjourney(配图生成),构建用户需求描述 → AI 生成图文报告 → 邮件发送的全流程自动化。
npm 包与 AI 框架支持:通过安装 Node.js 依赖(如langchain openai),扩展 AI 功能边界,例如:基于 LangChain 构建智能问答工作流:用户提问 → 检索企业知识库 → 生成包含内部数据的个性化回答,通过 Slack 自动回复。
工单自动化分类:用户提交工单 → AI 节点解析问题类型(如退款、技术支持)→ 自动分配负责人并生成回复模板(调用知识库节点),响应效率提升 70%;
客户情绪分析:社交媒体评论 → 情感分析节点打分 → 负面评价触发人工复核流程,同时自动汇总趋势报告。
电商商品描述批量生成:Excel 商品列表 → n8n 读取数据 → GPT 节点生成多语言描述 → Midjourney 节点生成展示图 → 同步至 Shopify 店铺,节省 80% 人工编辑时间;
个性化报告生成:数据库提取客户数据 → AI 节点按模板生成定制化分析报告(如投资组合月报)→ 自动加密发送至邮箱(集成 PDF 处理节点)。
代码安全审查:GitHub PR 提交 → n8n 调用 Codex 模型分析代码漏洞 → 自动评论风险点并触发 CI/CD 流程,减少人工审计成本;
智能监控与故障处理:Prometheus 指标 → AI 节点预测服务器负载异常 → 自动扩容 K8s 集群 + 发送带根因分析的报警(结合日志解析模型)。
n8n 提供了使用 Docker 镜像的部署方式,如下:
docker run -p 5678:5678 docker.n8n.io/n8nio/n8n
对于不熟悉 K8s 的伙伴,又想在 K8s 中安装 n8n,可以使用 Rainbond 来部署。Rainbond 是一个不用懂 Kubernetes 的开源容器平台,支持通过可视化界面管理容器化应用,提供应用市场一键部署、源码构建等能力,帮助用户在不接触 K8s 底层的前提下,轻松实现应用的生产级部署与运维。
免费试用 Rainbond Cloud(零门槛快速体验)
如果你想零成本快速上手云原生部署,推荐直接体验 Rainbond Cloud(点击注册 https://run.rainbond.com,新用户即享免费额度)—— 无需自备服务器或配置复杂环境,注册登录后,在云端环境中一键部署 n8n,5 分钟内即可开启智能工作流设计。
私有化本地部署(企业级可控性首选)
如果需要将 n8n 部署在自有服务器或数据中心(满足数据本地化、合规性要求),Rainbond 提供极简私有化部署方案,无需手动编写 K8s 配置,10 分钟内即可完成生产级环境搭建:
curl -o install.sh https://get.rainbond.com && bash ./install.sh
等待几分钟后,通过 http://IP:7070 访问 Rainbond 并注册登录。
通过应用市场一键部署 n8n
创建应用并选择通过应用市场部署,在开源应用商店中搜索n8n ,点击一键安装。
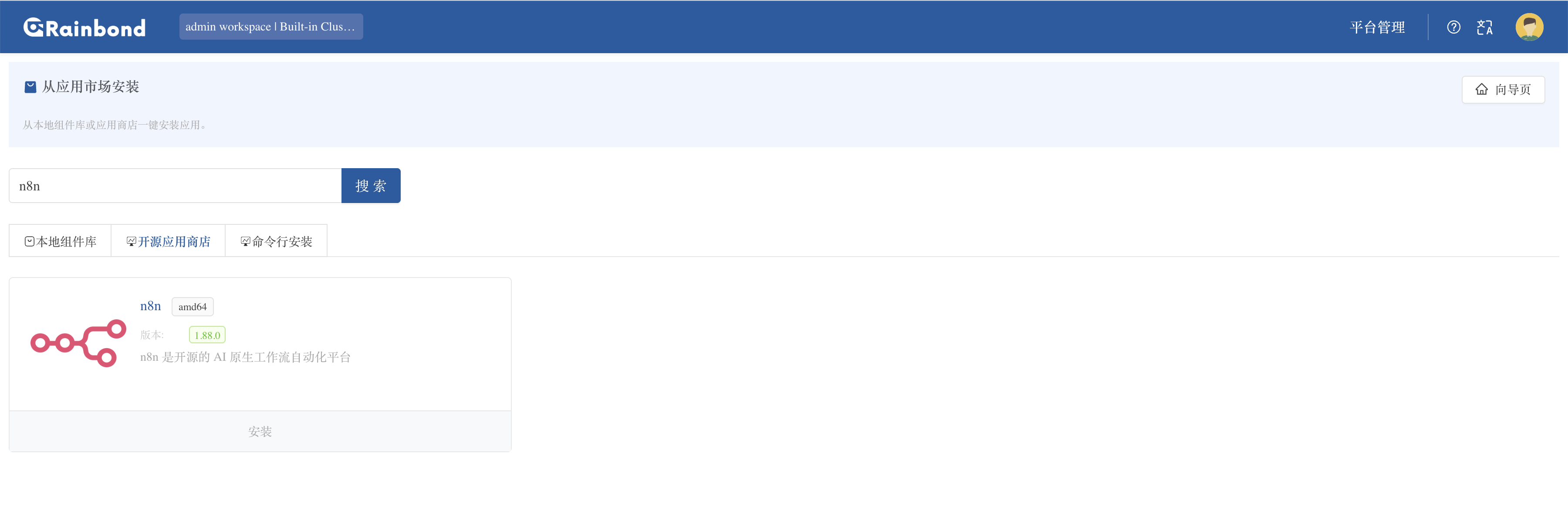
等待拓扑图中的组件颜色全部变为绿色则代表部署成功。
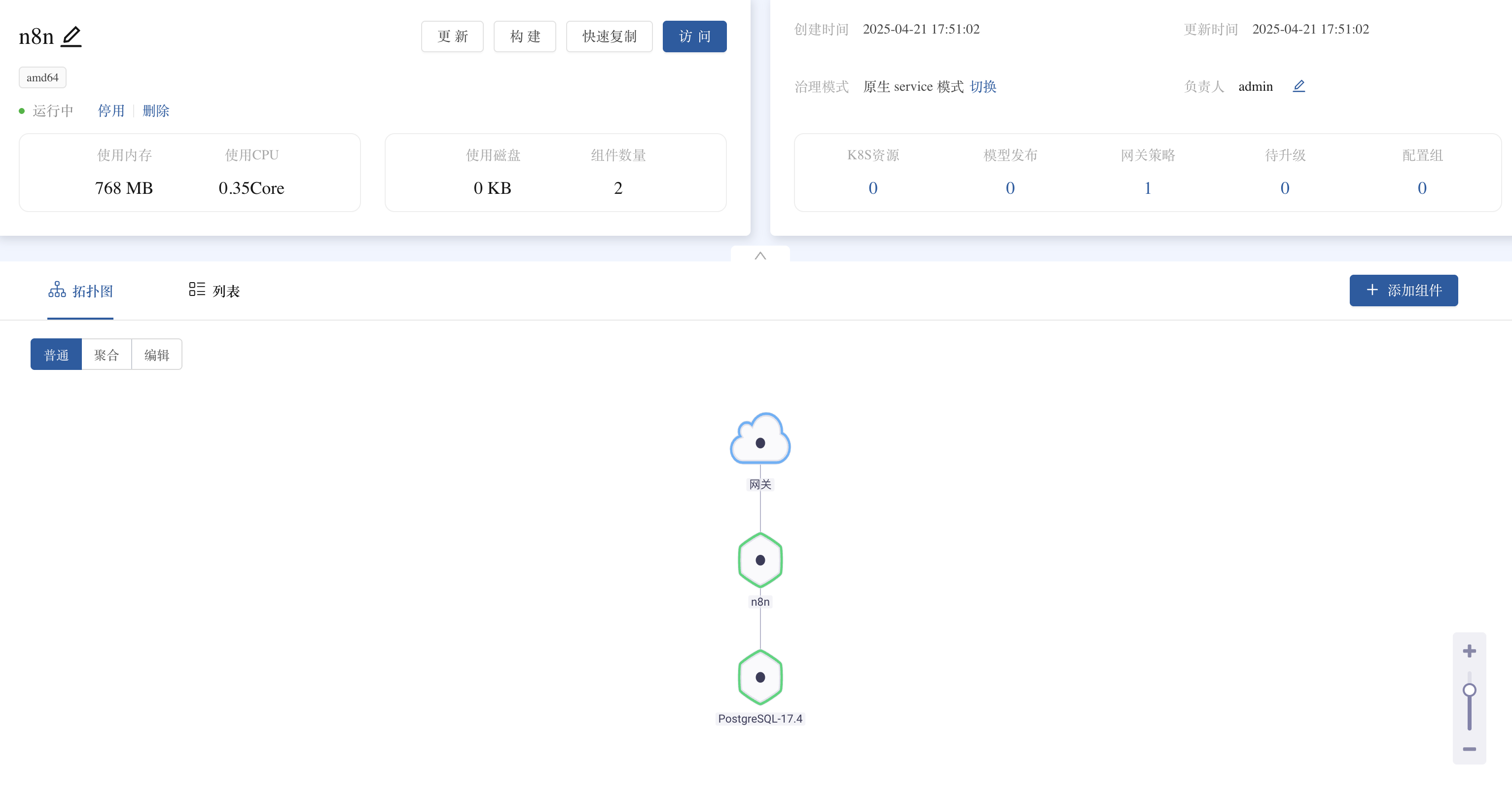 点击访问按钮即可通过平台生成的域名访问 n8n 可视化界面,注册即可开始设计工作流。
点击访问按钮即可通过平台生成的域名访问 n8n 可视化界面,注册即可开始设计工作流。
n8n 通过可视化 AI 节点降低门槛与代码扩展释放潜力的双重优势,让 AI 不再局限于独立工具,而是真正融入业务流程的每一个环节�。无论是个人开发者快速实现 AI 小工具,还是企业构建复杂的智能自动化系统,它都能通过高度可扩展的架构和丰富的生态,成为 AI 落地的 最后一公里解决方案。如果你正在寻找一款既能快速上手,又能满足深度定制的智能工作流平台,n8n 绝对是你的不二之选。
相信很多小伙伴对于 Cert Manager 不陌生,Cert Manager 是 Kubernetes 上的证书管理工具,基于 ACME 协议与 Let's Encrypt 签发免费证书并为证书自动续期,实现永久免费使用证书。
本文将介绍如何使用 Cert Manager 实现自动签发证书并与 Rainbond 结合使用。
在将 Cert Manager 部署到 Kubernetes 集群后,可以通过创建支持的自定义资源 CRD 来实现证书的签发和自动续期功能。以下是 Cert Manager 的工作机制概览:

Issuer 是 Cert Manager 用于定义证书签发方式的资源类型。它支持以下多种证书颁发机构:
Certificate 是 Cert Manager 的核心资源之一,用于定义需要签发的域名证书及其相关配置。它包含以下关键信息:
Issuer 或 ClusterIssuer。Secrets 是 Kubernetes 的资源对象,签发完成的证书最终会存储在 Secrets 中,供其他组件引用。
本文使用 Let’s Encrypt 作为证书颁发机构,Let’s Encrypt 利用 ACME 协议校验域名的归属,校验成功后可以自动颁发免费证书。免费证书有效期只有90天,默认情况下 Cert Manager 会在证书到期前30天自动续期,即实现永久使用免费证书。校验域名归属的两种方式分别是 HTTP-01 和 DNS-01。
HTTP-01:通过向域名的 HTTP 服务发送请求验证域名归属,适用于使用 Ingress 暴露流量的服务,但不支持泛域名证书。Cert Manager 会动态创建或修改 Ingress 规则,添加临时路径以响应 Let’s Encrypt 的验证请求。验证通过后颁发证书。
DNS-01:通过在 DNS 提供商处添加 TXT 记录验证域名归属,支持泛域名证书且无需 Ingress。Cert Manager 使用 DNS 提供商的 API 自动更新记录。Let’s Encrypt 查询 TXT 记录后完成验证并颁发证书。
| 特性 | HTTP-01 | DNS-01 |
|---|---|---|
| 是否依赖 Ingress | 是 | 否 |
| 是否支持泛域名 | 否 | 是 |
| 配置难度 | 简单,适用于所有 DNS 提供商 | 配置复杂,依赖 DNS 提供商的 API 支持 |
| 典型适用场景 | 仅服务通过 Ingress 暴露流量 | 需要泛域名证书或无 Ingress 的服务 |
使用 Helm 安装 Cert Manager,更多请参考Cert Manager 部署文档。
$ helm repo add jetstack https://charts.jetstack.io
$ helm install \
cert-manager jetstack/cert-manager \
--namespace cert-manager \
--create-namespace \
--version v1.16.2 \
--set crds.enabled=true
执行以下命令,快速安装 Rainbond。
curl -o install.sh https://get.rainbond.com && bash ./install.sh
Issuer 是 Cert Manager 的核心资源,用于定义证书的签发方式和配置。以下是一个示例,使用 HTTP-01 校验方式结合 Ingress 签发证书。
$ kubectl apply -f issuer.yaml
apiVersion: cert-manager.io/v1
kind: Issuer
metadata:
name: issuer # Issuer 的名称
namespace: default # 所在的命名空间
spec:
acme:
server: https://acme-v02.api.letsencrypt.org/directory # Let's Encrypt 的生产环境 ACME 服务地址
privateKeySecretRef:
name: issuer-account-key # 保存 ACME 私钥的 Kubernetes Secret
solvers: # 域名校验方式
- http01:
ingress:
ingressClassName: apisix # 使用 APISIX 作为 Ingress 控制器
Certificate 是 Cert Manager 的核心资源之一,用于指定需要签发的域名证书及其相关配置。以下是一个完整的配置示例,结合前面创建的 Issuer,为指定域名自动签发和续期证书。
以下 YAML 文件创建了一个 Certificate 资源,为域名 test.rainbond.com 签发证书:
$ kubectl apply -f certificate.yaml
apiVersion: cert-manager.io/v1
kind: Certificate
metadata:
name: test-rainbond-com # Certificate 资源的名称
namespace: default # 所在的命名空间
spec:
dnsNames:
- test.rainbond.com # 需要绑定证书的域名
issuerRef:
kind: Issuer # 引用的 Issuer 类型
name: issuer # 引用的 Issuer 名称
secretName: test-rainbond-com-tls # 存储签发的证书和私钥的 Secret 名称
创建 Certificate 后,可以通过以下步骤检查签发状态并获取证书内容:
kubectl get certificate 命令查看 Certificate 的状态:$ kubectl get certificate -n default
NAME READY SECRET AGE
test-rainbond-com True test-rainbond-com-tls 1m
True:表示证书签发成功。证书已保存在指定的 Secret 中。False:表示签发失败。需要进一步排查原因。READY 状态为 False,可以使用以下命令查看详细事件日志:kubectl describe certificate test-rainbond-com -n default
日志中会显示失败的原因,例如域名校验失败、配置错误或 Issuer 不可用。
READY 状态为 True 时,证书和密钥将保存在指定的 Secret 中。可以通过以下命令查看:$ kubectl get secret test-rainbond-com-tls -n default
NAME TYPE DATA AGE
test-rainbond-com-tls kubernetes.io/tls 2 1m
tls.crt: 证书内容。tls.key: 证书对应的私钥。$ kubectl get secret test-rainbond-com-tls -n default -o yaml
apiVersion: v1
kind: Secret
metadata:
name: test-rainbond-com-tls
namespace: default
data:
tls.crt: <base64 encoded certificate>
tls.key: <base64 encoded private key>
可以使用 base64 解码证书内容:
echo "<base64 encoded certificate>" | base64 -d
Rainbond v6 版本采用 APISIX 作为默认的 Ingress 控制器,通过配置 ApisixTls 资源即可轻松绑定证书,APISIX 会根据网关中的域名自动匹配对应的证书。
$ kubectl apply -f tls.yaml
apiVersion: apisix.apache.org/v2
kind: ApisixTls
metadata:
name: test-rainbond-com # 资源名称
namespace: default # 所在命名空间
spec:
hosts:
- test.rainbond.com # 绑定的域名
ingressClassName: apisix # 指定 Ingress 类名
secret:
name: test-rainbond-com-tls # 引用存储证书的 Secret 名称
namespace: default # 引用的 Secret 所在命名空间
在 Rainbond 页面上添加网关路由。进入网关管理 > 路由设置,创建一个新的路由,填写域名(如 test.rainbond.com)并完成路由配置。
Rainbond 会自动检测网关路由的域名是否与 ApisixTls 中的 hosts 匹配。如果匹配成功,将自动为该域名启用 HTTPS,并绑定对应的证书。
通过本文的介绍,我们详细了解了如何使用 Cert Manager 在 Kubernetes 中实现证书的自动签发与续期,并将其与 Rainbond 集成。Cert Manager 的灵活性与 Rainbond 的易用性结合,可以大大简化 HTTPS 的部署流程,为服务提供安全性保障。