Kubernetes 已成底座,为什么很多团队还是落不了地?
CNCF 最新年度调查已经把一个事实说得��很清楚:Kubernetes 基本已经坐稳了生产基础设施底座的位置。真正卡住团队的,越来越不是“要不要上 K8s”,而是“组织到底吃不吃得下它”。
很多团队今天遇到的尴尬,其实都很像。
项目启动会上,大家都认同要往云原生走。
架构师说 Kubernetes 已经是行业共识。
管理层也觉得这事迟早要做。
但几个月之后,真正推进起来,问题却不是出在技术路线,而是出在这些更现实的地方:
- 开发说,改个服务还得等运维;
- 运维说,大家都想上 K8s,但没人想先把这套复杂度接住;
- 业务说,为什么平台搭了,交付还是没变快;
- 交付团队说,每个客户还是像重新来一遍。
如果你们也有类似体感,那这篇文章可能比一篇“如何快速学会 K8s”更值得看。
因为今天最重要的问题,已经不是“你懂不懂 Kubernetes”,而是:
当 Kubernetes 成了底座之后,团队要靠什么,才能真的把它用起来。
先把外部结论说清楚
先看两个来自 CNCF 的明确信号。
信号 1:Kubernetes 已经不是前沿尝试,而是生产基础设施
CNCF 2026 年度调查显示,在使用容器的受访者里,82% 已经在生产环境运行 Kubernetes。
这意味着两件事:
- 讨论“要不要上 Kubernetes”这件事,意义已经在下降。
- 接下来真正拉开差距的,不是会不会装,而是会不会用、怎么组织起来用。
信号 2:真正的挑战,越来越不是工具本身
CNCF 官方解读这份调查时,直接给了一个很值得传播的判断:
culture, not complexity or security, is now the top barrier
翻译成人话就是:
今天很多团队落不了地,已经不只是因为技术复杂,而是因为组织接不住。
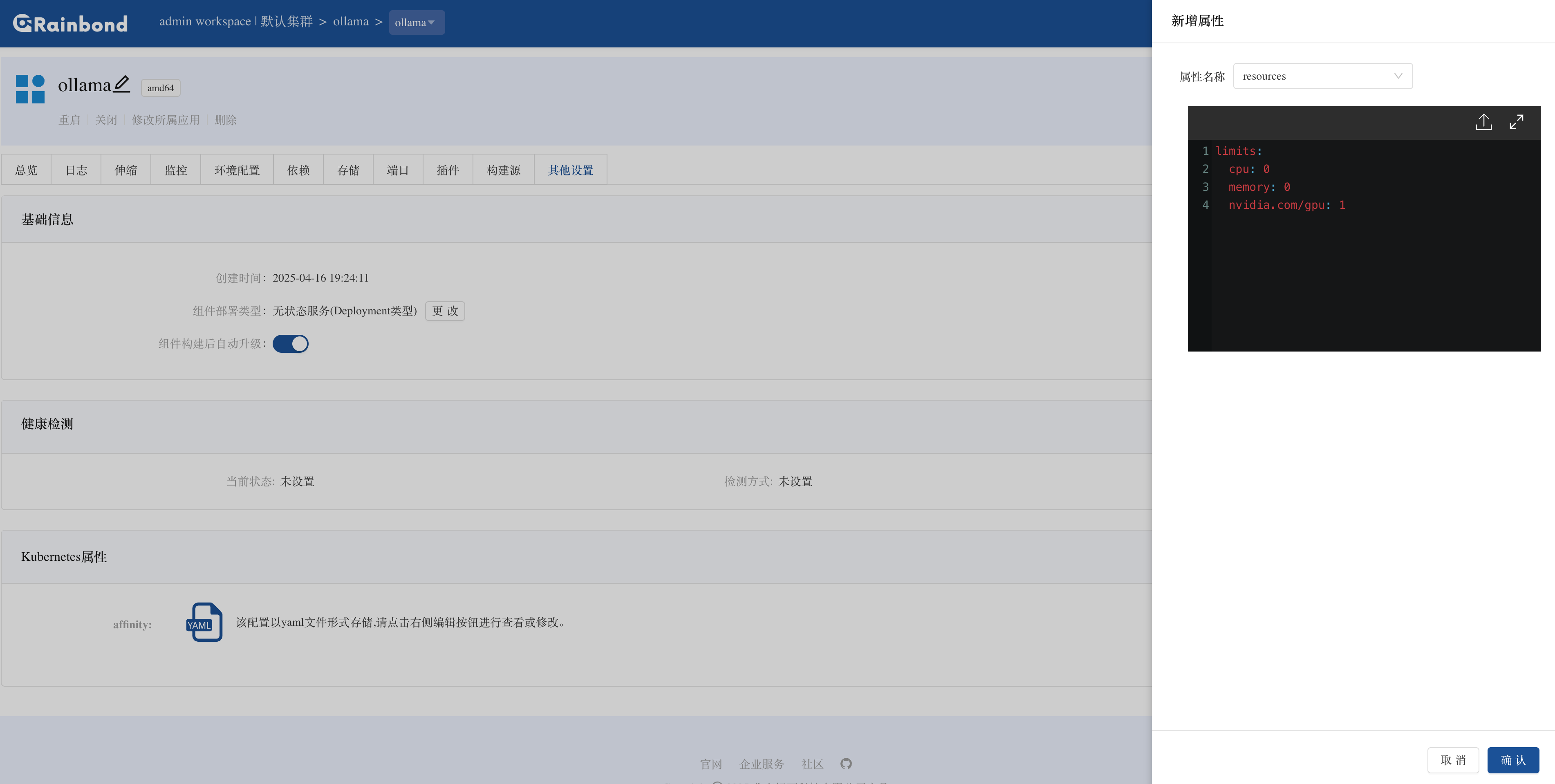
一张图看懂:问题已经从“技术门槛”转向“组织门槛”
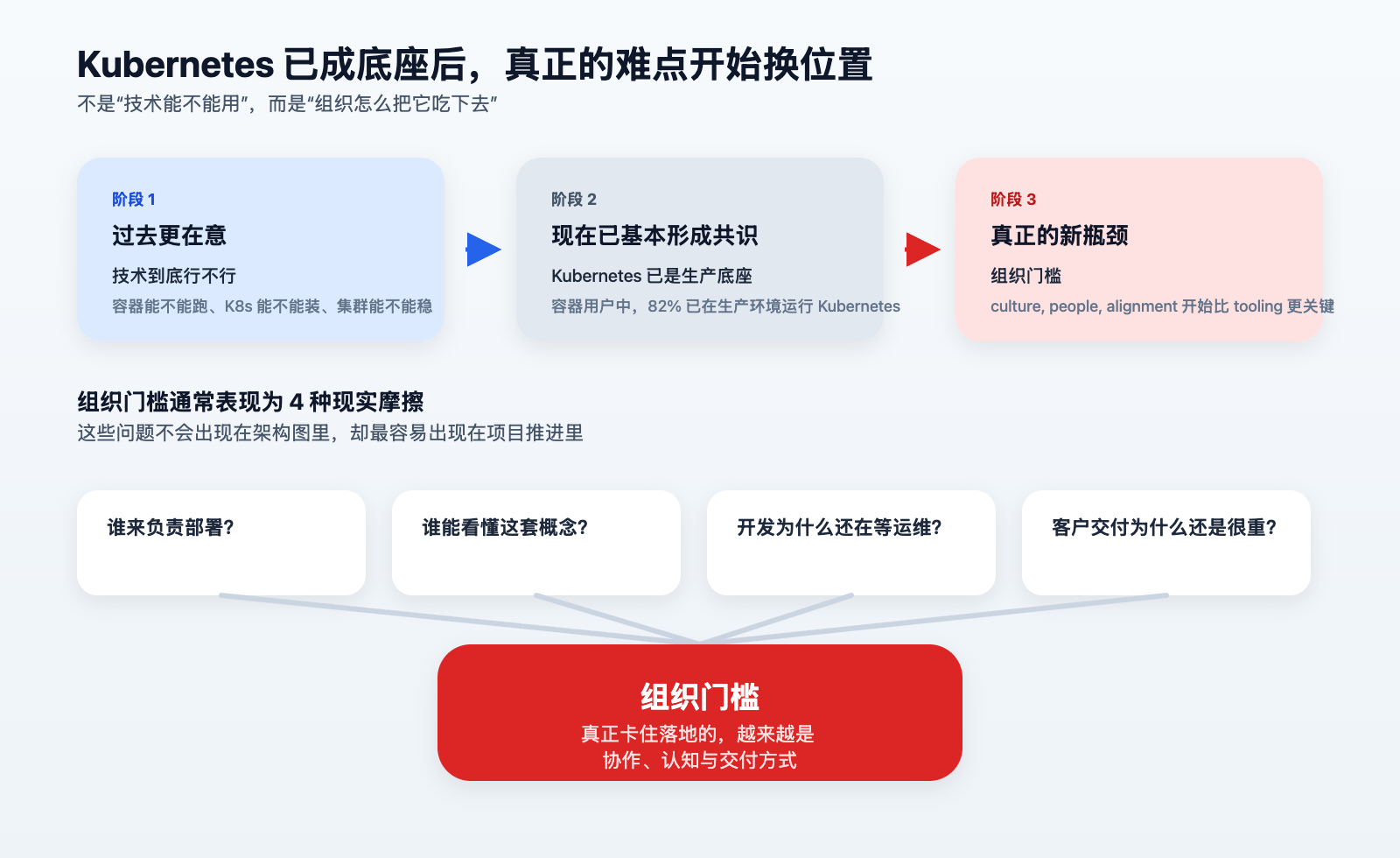
这张图里最关键的变化是:
- 以前大家在争“技术行不行”
- 现在更多团队在面对“组织怎么把技术吃下去”
这也是很多平台讨论经常讲偏的地方。
很多内容还在用一种默认前提写文章:
只要技术路线选对,团队自然会跟上。
现实通常没这么顺。
为什么很多团队明明认可 Kubernetes,却还是落不了地?
问题一般出在 4 个地方。
1. 技术共识有了,但角色边界没变
很多团队嘴上已经接受了云原生,但实际协作方式还是老路子:
- 开发写完代码,继续等运维发版;
- 运维继续做“平台翻译官”;
- 业务继续把交付当成后置动作。
结果就是,底层换成了 Kubernetes,上层流程却没变。
技术升级了,组织习惯没升级。
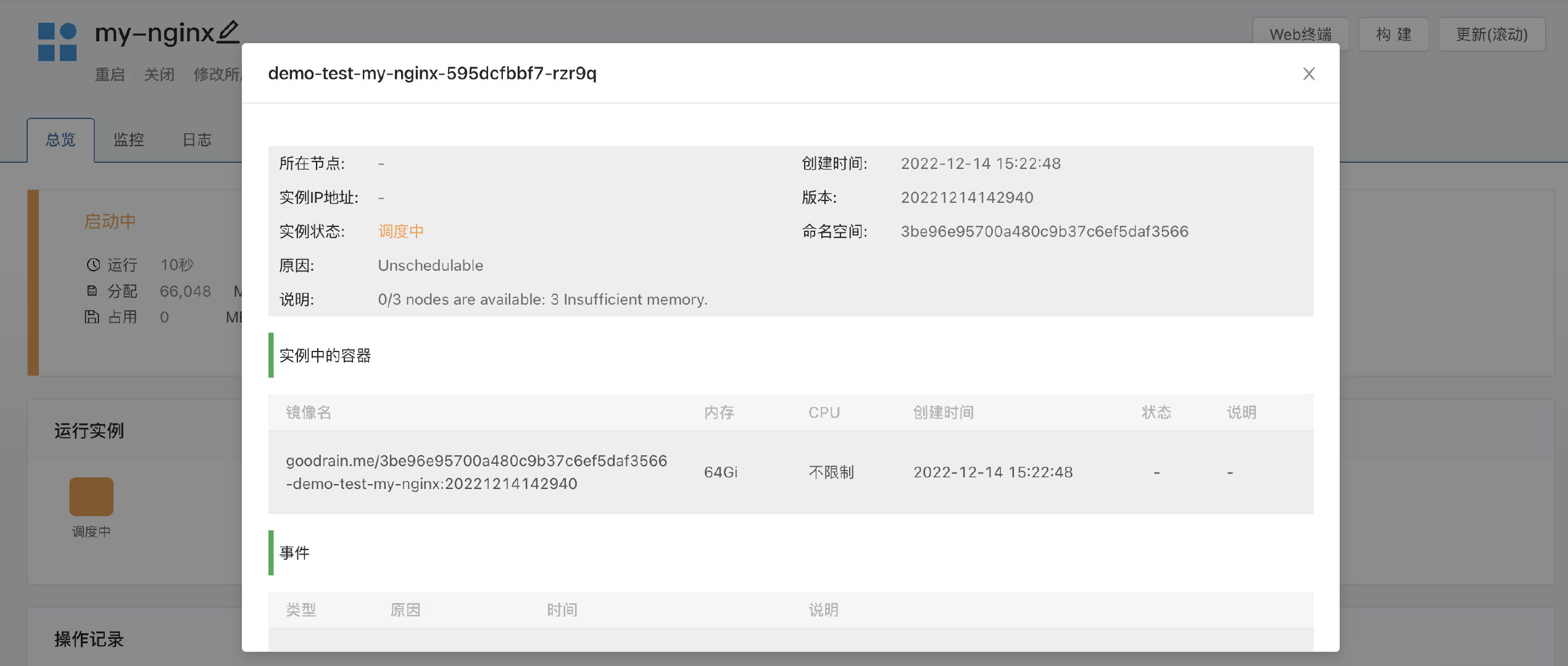
2. 平台搭起来了,但真正用的人没跟上
这在很多企业里都很常见。
平台团队把底层搭得很完整,功能也不差,但最后真正高频操作的�人依然只有少数几位运维或架构师。开发团队、测试团队、交付团队仍然觉得这套东西“不是给自己用的”。
这不是平台没价值,而是平台没有变成“大家愿意用、用得起、用得明白”的产品。
3. 大家都知道 K8s 很强,但不是每个团队都该先去学它
这一点很容易被误解。
Kubernetes 当然重要。
但“重要”和“需要每个人先学会”是两回事。
对于很多团队来说,当前最贵的问题根本不是“不会 Kubernetes”,而是:
- 交付链路太长;
- 环境信息太散;
- 部署动作太依赖少数人;
- 每次上线都像在做一个小项目。
如果这些问题不先解决,单纯把学习成本再叠上去,团队只会更累。
4. 对 ToB、私有化、内网场景来说,组织门槛会被放大
如果你所在的团队还涉及这些场景:
- 私有化部署
- 客户现场交付
- 多环境多集群
- 信创迁移
- 内外网隔离
那“Kubernetes 是底座”并不意味着事情更简单,反而意味着:
你更需要一层能把复杂度往后收、把交付流程往前拉平的平台。
谁更适合直接深上 Kubernetes,谁更适合先降低组织门槛?
这个问题特别重要,因为它决定了你到底该怎么开始。
| 团队状态 | 更适合的路径 | 原因 |
|---|---|---|
| 已有成熟平台团队、明确多集群治理需求 | 直接深做 Kubernetes 平台能力 | 团队有能力承接复杂度 |
| 研发人数不多、没人是全职 K8s 专家 | 先降低使用门槛 | 否则试点容易卡死在学习和协作成本上 |
| 传统企业信息化团队、供应商多、环境复杂 | 先把交付流程标准化 | 组织摩擦比底层技术更先出现 |
| ToB 厂商、私有化交付压力大 | 先把应用模板化、版本化 | 不然每个客户都像重新交付一遍 |
| 正在做云原生第一阶段试点 | 先跑通一个完整应用闭环 | 比“先搭一个完整平台”更现实 |
这里不是说“不要学 Kubernetes”。
而是说:
不要把“学 Kubernetes”误当成所有团队的第一步。
很多团队真正需要的第一步,其实是:
先找到一条不被 Kubernetes 复杂度拖死的落地路径。
这也是 Rainbond 最值�得被重新理解的地方
Rainbond 最容易被误解成一种“图形化界面更友好的容器平台”。
如果只这么理解,其实低估了它。
更准确的说法应该是:
当 Kubernetes 已经成为底座后,Rainbond 要解决的是“组织如何把这套底座真正吃下去”的问题。
它并不是去否定 Kubernetes,而是往上做了一层很关键的事情:
- 把底层概念往后收;
- 把应用视角往前提;
- 把开发、运维、交付之间的协作门槛降下来。
这意味着什么?
意味着很多团队不用先把所有人都训练成 Kubernetes 使用者,才能开始云原生试点。
他们可以先围绕“应用”工作:
- 从源码、软件包或镜像开始;
- 先把应用跑起来;
- 再去做版本、升级、回滚、日志、依赖和交付。
这对下面几类团队尤其重要:
- 中小研发团队;
- 传统企业信息化部门;
- 私有化 / 离线交付团队;
- 想做平台工程,但当前还在早期阶段的团队。
一张判断图:Rainbond 到底接住了哪一层问题?
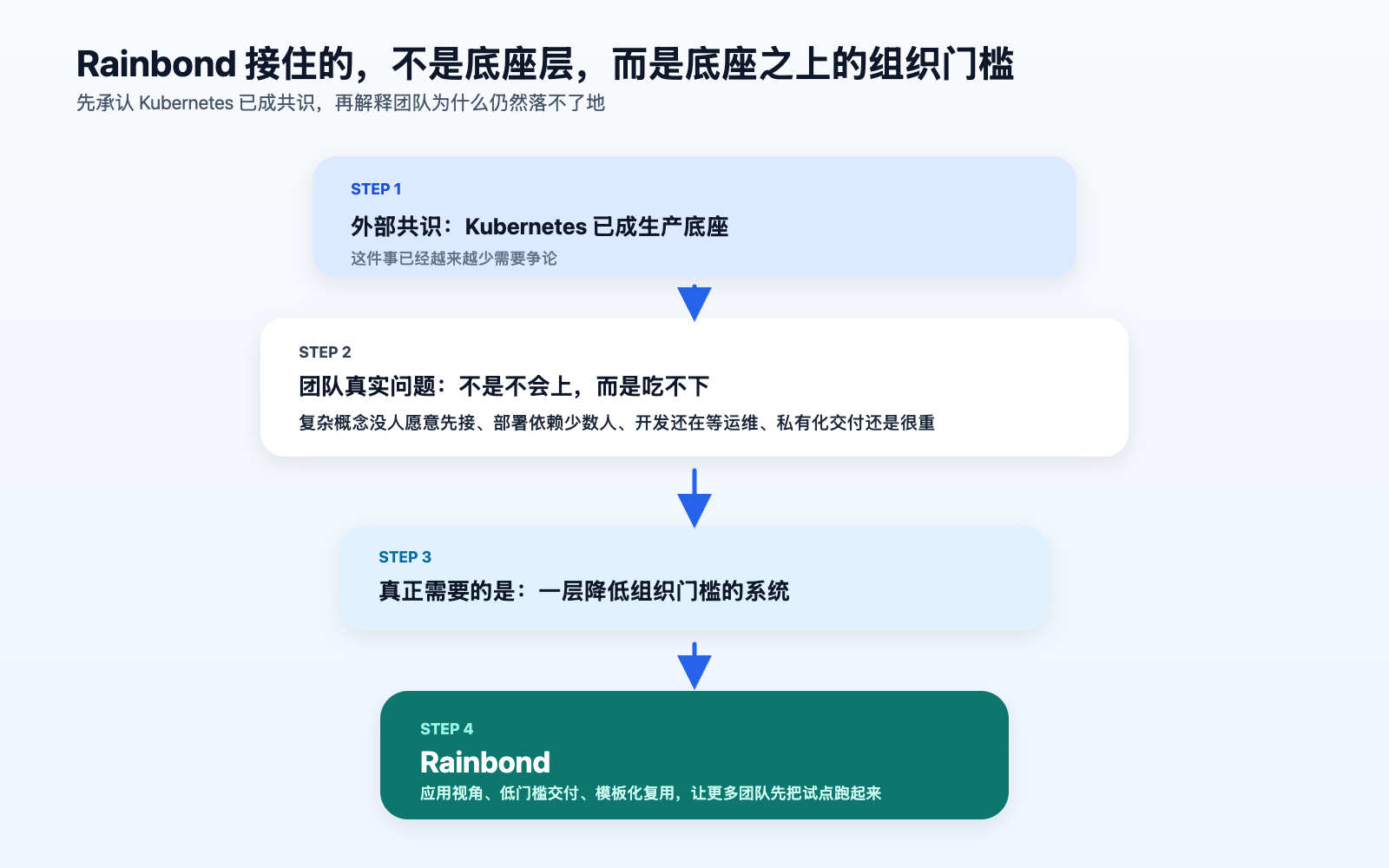
这张图想说明的不是“Rainbond 比 Kubernetes 更重要”。
恰恰相反。
它说明的是:
Kubernetes 的重要性已经被证明了,所以现在更重要的问题变成:谁来帮团队真正把它用起来。
Rainbond 就是在这个位置上有意义。
如果你是技术负责人,这篇文章真正该带走什么?
带走 3 个判断就够了。
判断 1:Kubernetes 已经不再是“是否值得”的问题
外部共识已经很强,继续争这个问题本身意义不大。
判断 2:接下来最关键的不是底座,而是组织门槛
你团队能不能真的推进,取决于:
- 谁来接复杂度;
- 谁来完成交付;
- 谁愿意真正用平台;
- 上线之后谁能维护住。
判断 3:如果你们当前最大的痛是“落不了地”,就别从最重的地方开始
很多团队失败,不是因为平台太弱,而是因为第一步走得太重。
如果你的团队现在最真实的问题是:
- 不想先把每个人都训练成 Kubernetes 专家;
- 想先跑通一个真实应用;
- 更在意交付效率,而不是先做复杂治理;
那 Rainbond 这种路径,通常比“先把整个团队压进底层复杂度”更现实。
最后一句话
今天最值得传播、也最值得记住的,不是:
“Kubernetes 很重要。”
而是:
当 Kubernetes 已成底座之后,真正把团队卡住的,越来越是人和组织。
而 Rainbond 的价值,恰好不在底座层,而在这层更难、也更现实的组织门槛上。