不会 Kubernetes 的团队,第一次把应用上线到底卡在哪?一次源码到部署实测给出答案
很多团队今天�已经不再怀疑 Kubernetes 值不值得学。
真正让人犯难的是另一件更具体的事:
代码写完了,第一次把应用上线,为什么还是像打一场配合并不默契的小型战役?
开发手里有仓库,运维手里有集群,测试催着要环境,负责人盯着时间点。真正落到动作层面,问题很快就会冒出来:
- 谁来补 Dockerfile
- 谁来把多模块项目拆成可运行单元
- 谁来配环境变量和依赖关系
- 谁来处理端口、访问入口、日志和回滚
- 谁来为第一次上线失败背锅
这也是为什么很多团队明明已经接受了云原生,第一次把应用真正跑起来,还是会觉得门槛高得不太对劲。
先看一个外部背景。
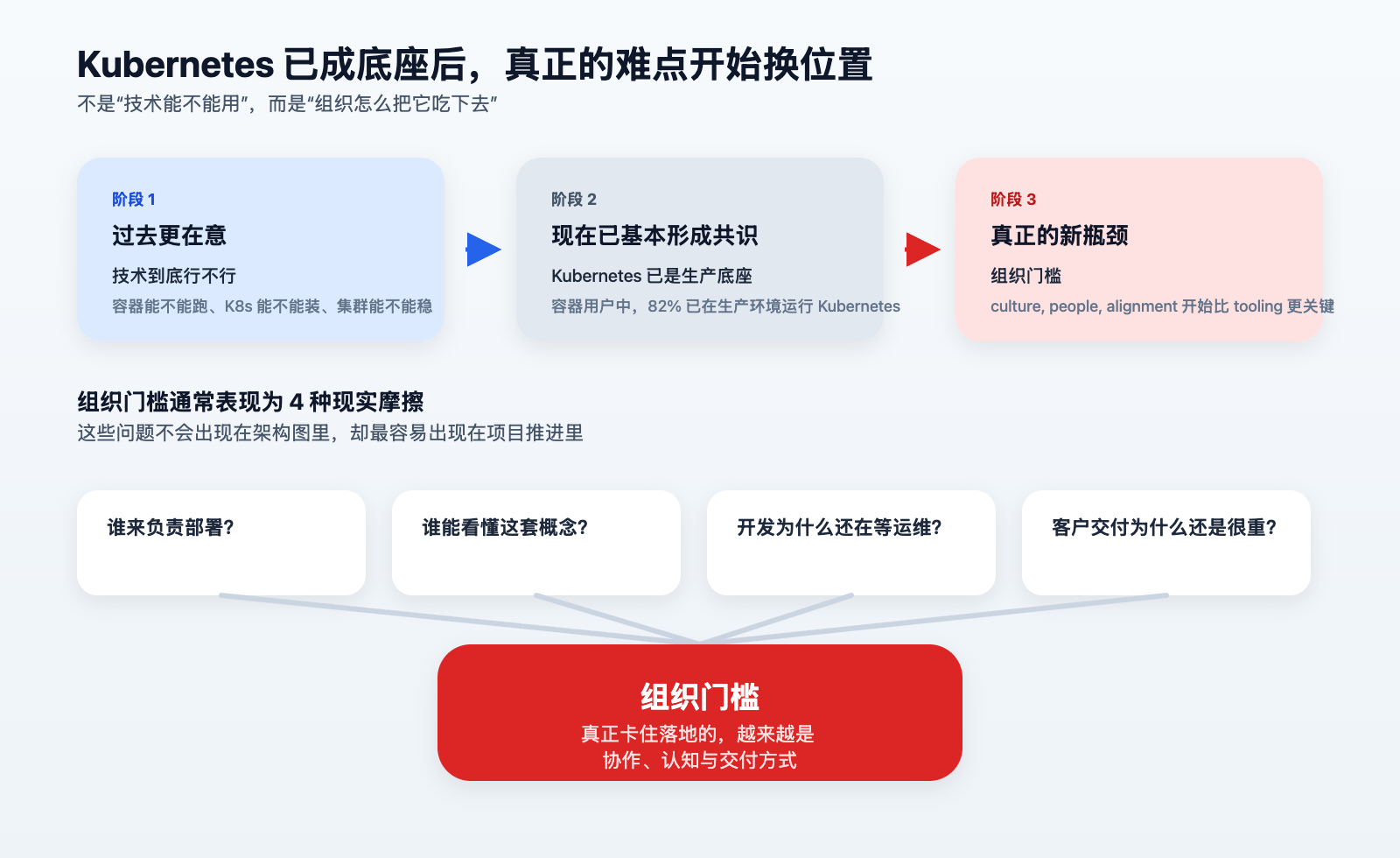
CNCF 在 2026 年 1 月发布的 2025 年度云原生调查里给出两个很关键的数字: 82% 的容器用户已经在生产环境运行 Kubernetes,98% 的受访组织已经采用云原生技术。另一边,Atlassian 在 2025 年针对 3,500 名开发者和管理者的调研也显示,AI 正在推高团队对交付效率的期待,但日常开发体验里的摩擦并没有自动消失。
这两个信号放在一起看,意思很明确:
很多团队现在卡住的,已经不是“要不要上 Kubernetes”,而是“能不能让一个不熟 Kubernetes 的开发团队,也顺利完成第一次上线”。
第一次上线,难的从来不只是“部署”
如果只把问题理解成“不会 K8s”,其实会把事情说简单了。
第一次上线真正难的,是一串动作被拆散到了太多对象里。
代码在仓库里,构建在流水线里,镜像在仓库里,端口和域名在网关里,依赖关系在环境变量里,日志在另一套系统里。开发想把一个服务跑起来,往往要跨过多套工具、多种概念和几轮角色切换。
这就导致一个非常常见的现象:
团队不是不会写业务,而是很难把“代码仓库里的东西”稳定地变成“线上可访问、可观察、可继续迭代的应用”。
尤其是下面几类项目,第一次上线的阻力会更明显:
- 多模块 Java 项目,不知道应该选哪个模块作为可运行入口
- 依赖 MySQL、Redis、MQ 之类中间件,配置靠手工拼
- 需要同时处理构建、启动、访问、日志、依赖关系
- 团队里没有全职 Kubernetes 专家,但上线压力已经摆在眼前
问题的根子,不在于开发者不够努力,而在于上线这件事长期是围绕底层对象展开的,而不是围绕“应用”本身展开的。
如果把第一次上线重新收束回“应用”,链路会变成什么样
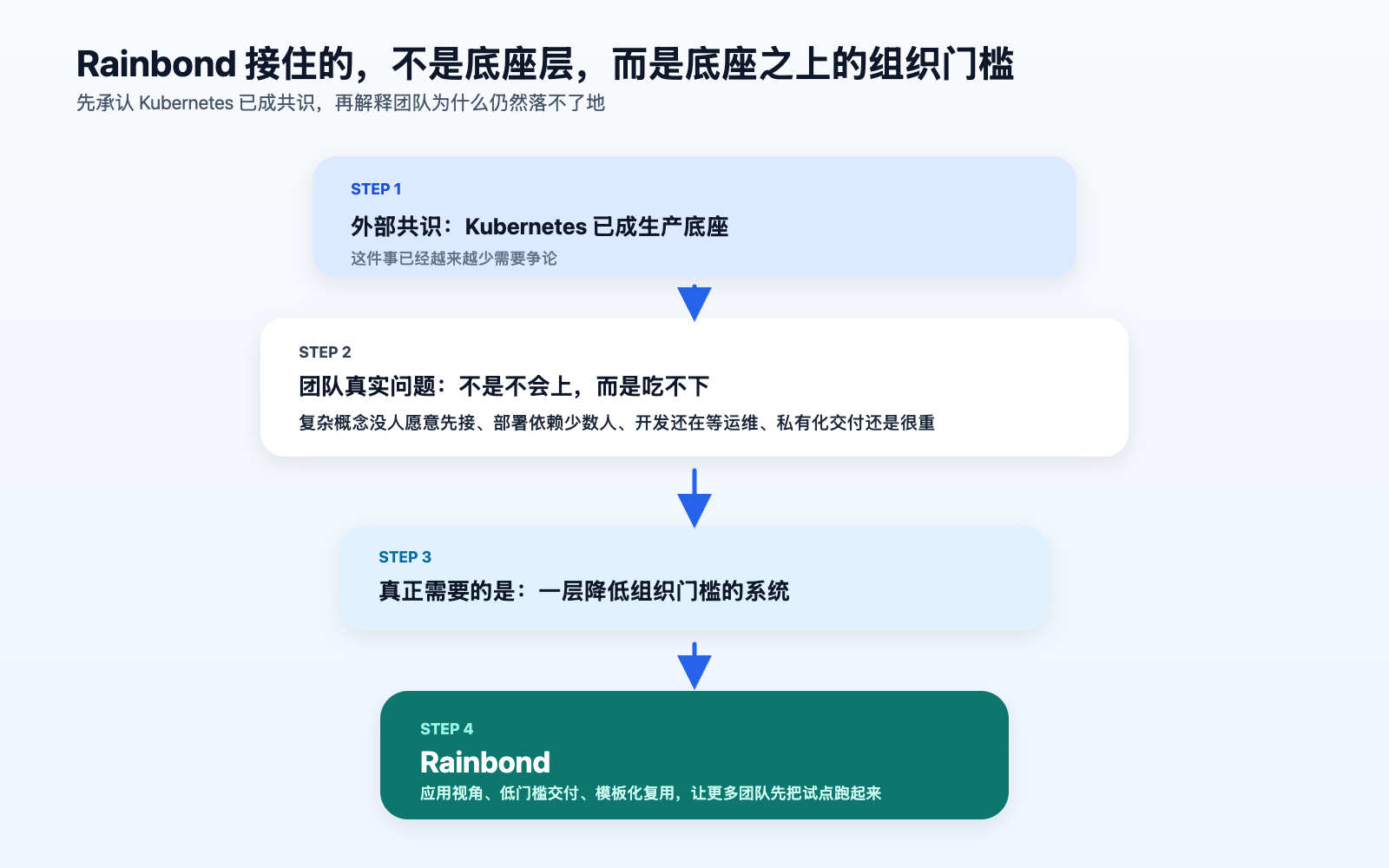
这也是 Rainbond 值得被放到这个话题里的原因。
它不是在否定 Kubernetes,也不是简单做一个“图形化界面更友好”的外壳。更准确地说,Rainbond 做的是一层应用级抽象: 底层仍然是 Kubernetes,但对开发团队暴露出来的,不再是大量零散的底层概念,而是更接近应用交付本身的动作。
这件事听上去有点抽象,放到真实链路里反而更容易理解。
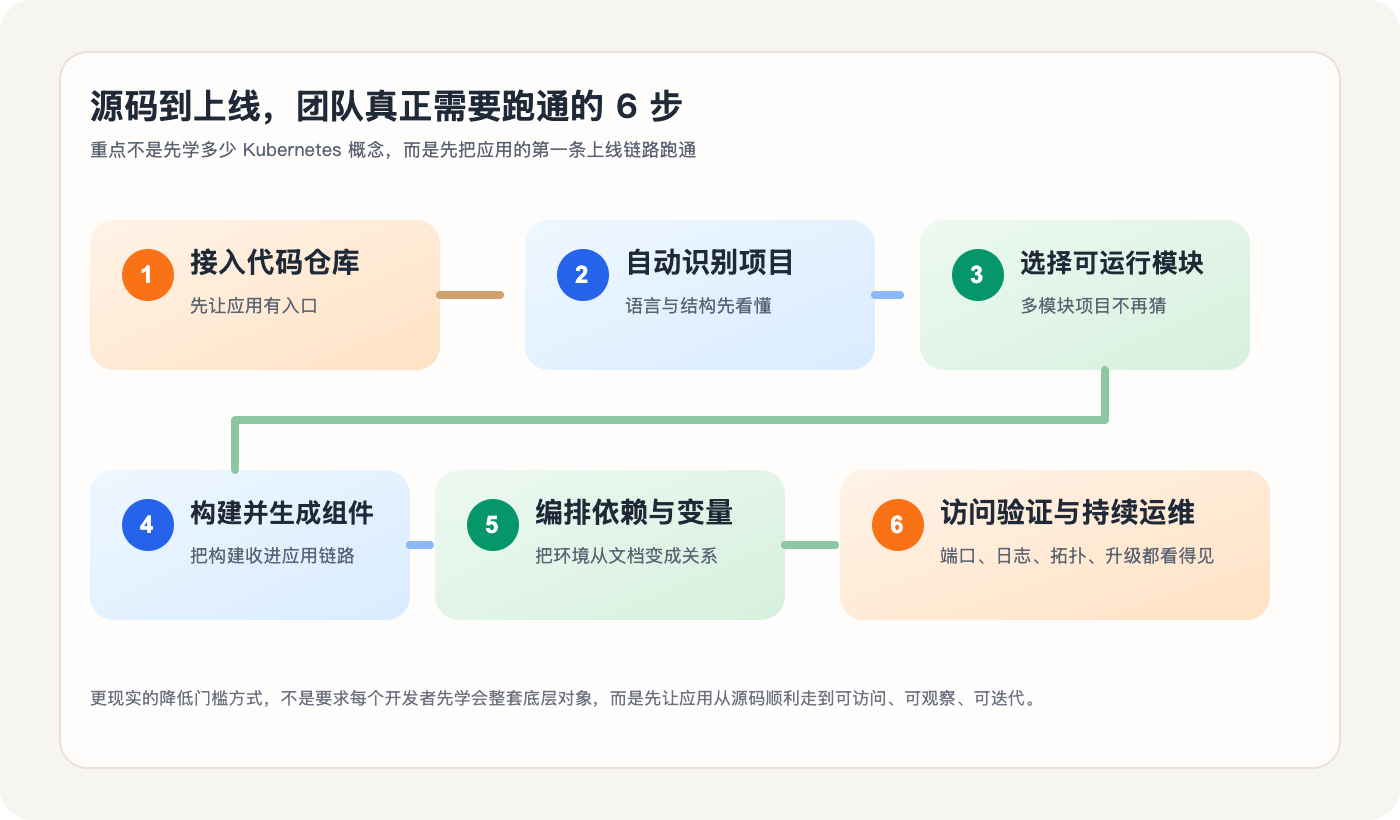
结合 Rainbond 官方文档里 mall 和 zyplayer-doc 两个案例,可以把“源码到上线”这条路拆成 6 步:
1. 从仓库开始,而不是先从容器细节开始
在 Rainbond 里,团队可以直接通过源码创建组件。对很多常见项目来说,这一步的入口是代码仓库地址,而不是先要求开发者把 Dockerfile、YAML 和一串部署脚本准备齐。
这看似只是入口变化,实际上非常重要。
因为它把第一次上线的起点,从“先理解底层打包和编排对象”,变成了“先让应用有一个可以被识别和托管的入口”。
2. 让平台先识别项目,而不是让人先记住一堆构建规则
在 zyplayer-doc 的案例里,Rainbond 会根据 pom.xml 识别项目结构,并判断多模块项目里哪个模块是可运行模块。
在 mall 的案例里,它会把 mall-admin、mall-portal、mall-search 这样的模块识别出来,再由使用者选择真正需要构建和上线的部分。
第一次上线最怕的,往往不是技术做不到,而是不知道从哪里下手。平台能先把项目结构识别出来,这本身就在替团队减少第一层试错成本。
3. 把“构建”收进应用链路,而不是交给每个人各自拼
很多团队第一次上线时会被构建动作拖住。
有人在项目里写镜像打包逻辑,有人另起 CI 任务,有人再补一层部署脚本。最后不是没有人会,而是每次都要重新拼一次。
Rainbond 的思路,是让构建动作跟应用组件直接关联起来。源码进入平台后,构建、生成可运行组件、进入后续部署流程,尽量在同一条应用链路里完成。
这对中小团队特别有价值。因为它减少的不是“高级能力”,而是第一次把事情跑通时最折磨人的碎片化动作。
4. 依赖关系和环境变量,不该再靠人肉搬运
第一次上线还有一个高频痛点: 代码能跑,环境总对不上。
数据库地址、Redis 密码、消息队列账号,很多时候都靠人手抄、群里发、文档里找。一次上线里最容易犯错的,恰恰是这些“不是代码、但又决定应用能不能跑”的信息。
在 Rainbond 的案例链路里,组件之间建立依赖后,相关环境变量会自动注入到应用组件中。对开发团队来说,这意味着依赖关系不再只是某份文档里的说明,而是应用编排里真实存在的一部分。
这一步很容易被低估。实际上,它直接影响第一次上线是否能少掉几轮无意义的排查。
5. 访问、日志、拓扑,不应该等上线后再东拼西凑
第一次上线最糟糕的体验,不是部署失败,而是“看不见自己到底部署成什么样了”。
服务有没有起来,依赖是否接通,端口是不是正确,访问入口对不对,日志在哪看,很多团队第一次上线时都要靠几种不同工具拼出来。
Rainbond 的应用视角有一个很直接的好处: 访问、日志、拓扑、生命周期管理这些动作,被放进了同一套界面和同一条工作流里。开发者不一定因此变成 Kubernetes 专家,但至少第一次上线不再像在几个系统之间来回跳。
6. 第一次上线之后,团队还能继续往前走
真正有价值的第一��次上线,不是“终于跑起来了”,而是“跑起来之后还能继续改、继续发、继续回看问题”。
Rainbond 对这个话题的意义,恰恰在这里。它不是只帮你把应用摆上去,而是把构建、部署、依赖、访问、日志、升级这些后续动作都收进应用生命周期里。这样第一次上线才不会变成一次性表演,而是成为后续迭代的起点。

这条路为什么会让“不懂 K8s 的团队”更容易迈出第一步
说到底,不是因为 Rainbond 把复杂度消灭了。
复杂度还在那里。集群、存储、网络、权限、可用性,这些底层问题依然存在,也依然需要有人负责。
但它重新分配了复杂度:
- 平台和运维团队去接住底层能力
- 开发团队围绕“应用”完成第一次上线
- 交付动作尽量收束在同一条可观察链路里
这和很多团队正在谈的平台工程,其实是同一个方向,只不过 Rainbond 更适合拿来解决一个很现实的起点问题:
别让第一次上线,就把团队拖进一整套底层对象的学习和协作泥潭。
哪些团队会对这条路径最有感
不是所有团队都需要用同一种方式开始。
但下面几类团队,通常会更容易从这种路径里得到收益:
| 团队状态 | 为什么更有感 |
|---|---|
| 研发人数不多,没有专职 Kubernetes 工程师 | 第一次上线最怕碎片化动作太多 |
| 正在把传统应用往云原生迁移 | 更需要低门槛入口,而不是先全面重写交付体系 |
| 私有化、内网或多环境交付较多 | 依赖、访问和生命周期动作更需要收束 |
| 想做平台工程,但还处在第一阶段 | 先跑通真实应用,比先堆满底层能力更重要 |
反过来,如果一个团队已经有成熟的平台团队、明确要深做底层治理、也习惯直接操作 Kubernetes 原生对象,那它当然可以继续走更底层的路径。
Rainbond 的意义,从来不是让所有人放弃 Kubernetes,而是给更多团队一个更现实的第一步。
最后真正该记住的一句话
今天很多团队第一次把应用上线,难的不是“代码能不能跑”,甚至也不只是“会不会 Kubernetes”。
真正难的,是怎么把源码、构建、依赖、访问和可观察性收束成一条普通开发团队也能驾驭的上线链路。
这也是 Rainbond 在这个话题里最值得被认真理解的地方:
它不是把 Kubernetes 换掉,而是在 Kubernetes 之上,把第一次上线这�件事重新变回“围绕应用”的工作。
对于那些已经接受云原生、却还在第一次上线这一步频繁卡住的团队来说,这往往比再多学几个底层概念,更接近问题本身。